
 科普中國(guó)公眾號(hào)
科普中國(guó)公眾號(hào)
 科普中國(guó)微博
科普中國(guó)微博

 幫助
幫助 隨著人工智能和深度學(xué)習(xí)逐漸進(jìn)入人們視野,中科院、谷歌、IBM、英偉達(dá)等中美科研機(jī)構(gòu)和商業(yè)公司也紛紛推出了用于深度學(xué)習(xí)的處理器。在上述產(chǎn)品中,既有CPU、GPU、DSP這樣的傳統(tǒng)芯片,也有專門為深度學(xué)習(xí)而生的NPU。那么,CPU、GPU、DSP、NPU等深度學(xué)習(xí)處理器各有什么特點(diǎn),這些深度學(xué)習(xí)處理器誰(shuí)更出彩呢?
CPU、GPU、DSP:以現(xiàn)有的技術(shù)進(jìn)行微調(diào)
在英偉達(dá)開(kāi)發(fā)出針對(duì)人工智能的定制GPU,并堅(jiān)持DGX-1 系統(tǒng)之后,Intel也不甘落后,在收購(gòu)深度學(xué)習(xí)創(chuàng)業(yè)公司 Nervana Systems之后,Intel也公布了用于深度學(xué)習(xí)的Xeon Phi家族新成員,在深度學(xué)習(xí)處理器領(lǐng)域開(kāi)辟新戰(zhàn)場(chǎng)。之后Intel和英偉達(dá)更是先后宣稱自己的產(chǎn)品優(yōu)于對(duì)方的產(chǎn)品,在輿論上打起來(lái)口水戰(zhàn)。雖然現(xiàn)階段短時(shí)間看還是GPU有優(yōu)勢(shì)——Intel的眾核芯片也在一定程度上吸取了GPU的優(yōu)勢(shì)。不過(guò),無(wú)論是針對(duì)人工智能的眾核芯片還是定制版的GPU,本質(zhì)上都不是專用處理器,實(shí)際上是拿現(xiàn)有的、相對(duì)成熟的架構(gòu)和技術(shù)成果去應(yīng)對(duì)新生的人工智能,并沒(méi)有發(fā)生革命性的技術(shù)突破。
6月20日,中星微“數(shù)字多媒體芯片技術(shù)”國(guó)家重點(diǎn)實(shí)驗(yàn)室在京宣布,中國(guó)首款嵌入式NPU(神經(jīng)網(wǎng)絡(luò)處理器)芯片誕生,目前已應(yīng)用于全球首款嵌入式視頻處理芯片“星光智能一號(hào)”。不過(guò),在經(jīng)過(guò)仔細(xì)分析后,所謂“中國(guó)首款嵌入式神經(jīng)網(wǎng)絡(luò)處理器”很有可能是一款可以運(yùn)行神經(jīng)網(wǎng)絡(luò)的DSP,而非真正意義的神經(jīng)網(wǎng)絡(luò)專用芯片。
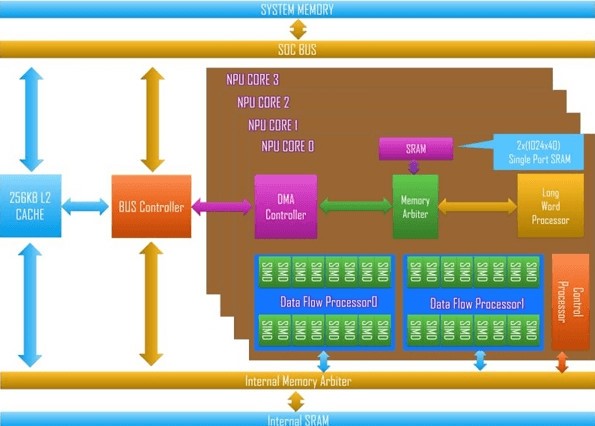
上圖是星光智能一號(hào)發(fā)布的系統(tǒng)架構(gòu)圖,共包含四個(gè)NPU核,每個(gè)NPU核包含4個(gè)內(nèi)核,每個(gè)內(nèi)核有兩個(gè)流處理器(Dataflow Processor),每個(gè)流處理器具有8個(gè)長(zhǎng)位寬或16位寬的SIMD運(yùn)算單元。每個(gè)NPU核的峰值性能為38Gops(16位定點(diǎn))或者76Gops(8位定點(diǎn))。除了多核流處理器本身用于完成卷積運(yùn)算外,星光智能一號(hào)集成了一個(gè)超長(zhǎng)指令字(VLIW)處理器用于完成神經(jīng)網(wǎng)絡(luò)中的超越函數(shù)等運(yùn)算。另有256KB的L2Cache以及DMA模塊用于大塊數(shù)據(jù)的搬移。
從其低位寬的定點(diǎn)運(yùn)算器推斷,星光智能一號(hào)僅可支持神經(jīng)網(wǎng)絡(luò)正向運(yùn)算,無(wú)法支持神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。從片上存儲(chǔ)結(jié)構(gòu)看,星光智能一號(hào)基于傳統(tǒng)的片上緩存(Cache),而非像最近流行的神經(jīng)芯片或FPGA方案一樣使用便簽式存儲(chǔ)。因此,在技術(shù)上看星光智能一號(hào)是典型的“舊瓶裝新酒”方案,將傳統(tǒng)的面向數(shù)字信號(hào)處理的DSP處理器架構(gòu)用于處理神經(jīng)網(wǎng)絡(luò),主要在運(yùn)算器方面作了相應(yīng)修改,例如低位寬和超越函數(shù),而并非是“狹義的”神經(jīng)網(wǎng)絡(luò)專用處理器。
因此,星光智能一號(hào)其實(shí)是DSP,而非NPU。其實(shí),Cadence公司的Tensilica Vision P5處理器、Synopsys公司的EV處理器和星光一號(hào)如出一轍,也是將傳統(tǒng)的面向數(shù)字信號(hào)處理的DSP處理器架構(gòu)用于處理神經(jīng)網(wǎng)絡(luò),主要在運(yùn)算器方面作了相應(yīng)修改,例如低位寬和超越函數(shù),而并非真正的NPU,能夠適用于卷積神經(jīng)網(wǎng)路(CNN),而對(duì)循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)等處理語(yǔ)音和自然語(yǔ)言的網(wǎng)絡(luò)有可能就無(wú)能為力了。
總之,Intel、英偉達(dá)、Synopsys公司、Cadence公司等都是在使用現(xiàn)有的比較成熟的技術(shù)去滿足深度學(xué)習(xí)的需求,眾核芯片和定制版GPU在本質(zhì)上來(lái)說(shuō)依舊是CPU和GPU,而并非專門針對(duì)深度學(xué)習(xí)的專業(yè)芯片,Synopsys公司和Cadence用傳統(tǒng)SIMD/DSP架構(gòu)來(lái)適配神經(jīng)網(wǎng)絡(luò),和真正的NPU依然有一定差距。打一個(gè)比方,用眾核芯片、GPU、DSP跑深度學(xué)習(xí),就類似于用轎車去拉貨,受轎車自身特點(diǎn)的限制,貨物運(yùn)輸能力與真正大馬力、高負(fù)載的貨車有一定差距。同理,即便是因?yàn)榧夹g(shù)相對(duì)更加成熟,Intel和英偉達(dá)的芯片在集成度和制造工藝上具有優(yōu)勢(shì),但由于CPU、GPU、DSP并非針對(duì)深度學(xué)習(xí)的專業(yè)芯片,相對(duì)于專業(yè)芯片,其運(yùn)行效率必然受到一定影響。
NPU:為深度學(xué)習(xí)而生的專業(yè)芯片
人工神經(jīng)網(wǎng)絡(luò)是一類模仿生物神經(jīng)網(wǎng)絡(luò)而構(gòu)建的計(jì)算機(jī)算法的總稱,由若干人工神經(jīng)元結(jié)點(diǎn)互聯(lián)而成。神經(jīng)元之間通過(guò)突觸兩兩連接,突觸記錄了神經(jīng)元間聯(lián)系的權(quán)值強(qiáng)弱。
每個(gè)神經(jīng)元可抽象為一個(gè)激勵(lì)函數(shù),該函數(shù)的輸入由與其相連的神經(jīng)元的輸出以及連接神經(jīng)元的突觸共同決定。為了表達(dá)特定的知識(shí),使用者通常需要(通過(guò)某些特定的算法)調(diào)整人工神經(jīng)網(wǎng)絡(luò)中突觸的取值、網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)等。該過(guò)程稱為“學(xué)習(xí)”。在學(xué)習(xí)之后,人工神經(jīng)網(wǎng)絡(luò)可通過(guò)習(xí)得的知識(shí)來(lái)解決特定的問(wèn)題。
由于深度學(xué)習(xí)的基本操作是神經(jīng)元和突觸的處理,而傳統(tǒng)的處理器指令集(包括x86和ARM等)是為了進(jìn)行通用計(jì)算發(fā)展起來(lái)的,其基本操作為算術(shù)操作(加減乘除)和邏輯操作(與或非),往往需要數(shù)百甚至上千條指令才能完成一個(gè)神經(jīng)元的處理,深度學(xué)習(xí)的處理效率不高。因此谷歌甚至需要使用上萬(wàn)個(gè)x86 CPU核運(yùn)行7天來(lái)訓(xùn)練一個(gè)識(shí)別貓臉的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)。因此,傳統(tǒng)的通用處理器(包括x86和ARM芯片等)用于深度學(xué)習(xí)的處理效率不高,這時(shí)就必須去研發(fā)面向深度學(xué)習(xí)的專用處理器。
中國(guó)科學(xué)院計(jì)算技術(shù)研究所是國(guó)際上最早研究深度神經(jīng)網(wǎng)絡(luò)處理器的單位之一。2014年,中科院計(jì)算所和法國(guó)Inria合作發(fā)表的相關(guān)學(xué)術(shù)論文先后獲得了計(jì)算機(jī)硬件領(lǐng)域頂級(jí)會(huì)議ASPLOS’14和MICRO’14的最佳論文獎(jiǎng)。這也是亞洲首次在此領(lǐng)域頂級(jí)會(huì)議上獲得最佳論文獎(jiǎng)。
隨后,國(guó)際計(jì)算機(jī)學(xué)會(huì)(Association for Computing Machinery)通訊也將這一系列工作列為計(jì)算機(jī)領(lǐng)域的研究焦點(diǎn)。這標(biāo)志著我國(guó)在智能芯片領(lǐng)域已經(jīng)進(jìn)入了國(guó)際領(lǐng)先行列。此后中科院計(jì)算所獨(dú)立研制了世界首個(gè)深度學(xué)習(xí)處理器芯片---寒武紀(jì),發(fā)布了世界首個(gè)神經(jīng)網(wǎng)絡(luò)處理器指令集,后者于2016年被計(jì)算機(jī)體系結(jié)構(gòu)領(lǐng)域頂級(jí)國(guó)際會(huì)議ISCA2016(International Symposiumon Computer Architecture)所接收,其評(píng)分排名所有近300篇投稿的第一名。
寒武紀(jì)相對(duì)于CPU和GPU究竟有哪些優(yōu)勢(shì)呢?寒武紀(jì)公司發(fā)布的Cambricon指令集直接面對(duì)大規(guī)模神經(jīng)元和突觸的處理,一條指令即可完成一組神經(jīng)元的處理,并對(duì)神經(jīng)元和突觸數(shù)據(jù)在芯片上的傳輸提供了一系列專門的支持。寒武紀(jì)專用處理器面向深度學(xué)習(xí)應(yīng)用專門定制了功能單元和片上存儲(chǔ)層次,同時(shí)剔除了通用處理器中為支持多樣化應(yīng)用而加入的復(fù)雜邏輯(如動(dòng)態(tài)流水線等),因此與CPU、GPU相比,神經(jīng)網(wǎng)絡(luò)專用處理器會(huì)有百倍以上的性能或能耗比差距。
雖然寒武紀(jì)公司和中科院計(jì)算所尚未公布其商用產(chǎn)品,但我們可以從中科院計(jì)算所與法國(guó)Inria合作在2014年公開(kāi)發(fā)表于ASPLOS2014學(xué)術(shù)會(huì)議的DianNao深度學(xué)習(xí)加速器架構(gòu)看出一些端倪。DianNao為單核架構(gòu),主頻為0.98GHz,峰值性能達(dá)每秒4520億次神經(jīng)網(wǎng)絡(luò)基本運(yùn)算,65nm工藝下功耗為0.485W,面積3.02mm^2。在若干代表性神經(jīng)網(wǎng)絡(luò)上的實(shí)驗(yàn)結(jié)果表明,DianNao的平均性能超過(guò)主流CPU核的100倍,但是面積和功耗僅為1/10,效能提升可達(dá)三個(gè)數(shù)量級(jí);DianNao的平均性能與主流GPGPU相當(dāng),但面積和功耗僅為主流GPGPU百分之一量級(jí)。

(寒武紀(jì)板卡)
在NPU上中國(guó)領(lǐng)先美國(guó)
由于IBM很不幸的點(diǎn)歪了科技樹(shù),這直接導(dǎo)致中國(guó)在NPU上暫時(shí)領(lǐng)先于美國(guó)。
真北本身的研究是基于脈沖神經(jīng)網(wǎng)絡(luò)(Spiking Neural Network,SNN)的,而寒武紀(jì)則一直面向的是機(jī)器學(xué)習(xí)類的神經(jīng)網(wǎng)絡(luò),如MLP(多層感知機(jī))、CNN(卷積神經(jīng)網(wǎng)絡(luò))和DNN(深度神經(jīng)網(wǎng)絡(luò))。
兩種網(wǎng)絡(luò)根本的不同在于網(wǎng)絡(luò)中傳遞的信息的表示,前者(SNN)是通過(guò)脈沖的頻率或者時(shí)間,后者則是突觸連接的權(quán)值。目前在現(xiàn)有的測(cè)試集上,機(jī)器學(xué)習(xí)類的神經(jīng)網(wǎng)絡(luò)具有更高的精度(尤其是深度神經(jīng)網(wǎng)絡(luò));前者則在精度上不能與之比擬。
精度是目前領(lǐng)域內(nèi)很關(guān)心的非常重要的指標(biāo),比如近幾年火熱的ImageNet競(jìng)賽也是以識(shí)別精度為衡量標(biāo)準(zhǔn)的。正是因?yàn)樵?jīng)存在精度方面的差距,所以后來(lái)IBM的真北放棄了原來(lái)的路線圖,也開(kāi)始貼近機(jī)器學(xué)習(xí)類的神經(jīng)網(wǎng)絡(luò),并采用了一些很曲折的方法來(lái)實(shí)現(xiàn)這一目標(biāo)。
之前說(shuō)過(guò),真北本身是基于脈沖神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)的,并且采用了邏輯時(shí)鐘為1KHz這樣的低頻率來(lái)模擬毫秒級(jí)別生物上的脈沖,這也使得真北功耗很低(70mW),當(dāng)然性能也比較有限。而寒武紀(jì)則是機(jī)器學(xué)習(xí)類的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì),運(yùn)行時(shí)鐘頻率在GHz左右,能夠極其快速且高效的處理網(wǎng)絡(luò)計(jì)算。這使得寒武紀(jì)相對(duì)于真北具有性能上的優(yōu)勢(shì)。
相比之下,寒武紀(jì)系列的內(nèi)部計(jì)算完全符合機(jī)器學(xué)習(xí)類神經(jīng)網(wǎng)絡(luò)(機(jī)器學(xué)習(xí)類網(wǎng)絡(luò)本身也沒(méi)有如同脈沖神經(jīng)網(wǎng)絡(luò)一樣特別貼合生物神經(jīng)元模型),通過(guò)調(diào)度在不同時(shí)刻計(jì)算不同的神經(jīng)元從而完成整個(gè)神經(jīng)網(wǎng)絡(luò)的計(jì)算。這其中,涉及到處理器設(shè)計(jì)本身的一點(diǎn)是,通過(guò)不同參數(shù)的選取就能夠完成不同規(guī)格(處理能力)的處理器實(shí)現(xiàn)。
筆者曾采訪過(guò)杜子?xùn)|博士(杜子?xùn)|博士長(zhǎng)期從事人工神經(jīng)網(wǎng)絡(luò)和脈沖神經(jīng)網(wǎng)絡(luò)處理器的研究工作,在處理器架構(gòu)最好的三個(gè)國(guó)際頂級(jí)會(huì)議ISCA/MICRO/ASPLOS上發(fā)表過(guò)多篇論文,是中國(guó)計(jì)算機(jī)體系結(jié)構(gòu)領(lǐng)域青年研究者中的翹楚),杜子?xùn)|博士表示,“包括他們(IBM)在內(nèi),大家都認(rèn)為他們(IBM)走錯(cuò)了路......”,并認(rèn)為,“真北相對(duì)于寒武紀(jì)沒(méi)有什么優(yōu)勢(shì)。硬要說(shuō)有的話,那就是IBM的品牌優(yōu)勢(shì)和廣告優(yōu)勢(shì)”。
結(jié)語(yǔ)
就深度學(xué)習(xí)處理器而言,美國(guó)可以憑借其在CPU和GPU上深厚的技術(shù)積累,并在芯片集成度和制造工藝水平占據(jù)絕對(duì)優(yōu)勢(shì)的情況下,開(kāi)發(fā)出能用于深度學(xué)習(xí),且性能不俗的眾核芯片和GPGPU,而且這些美國(guó)IT巨頭會(huì)利用他們巨大體量和市場(chǎng)推廣、銷售能力,大力推廣用這些傳統(tǒng)芯片來(lái)進(jìn)行深度學(xué)習(xí)處理,在商業(yè)上能拔得頭籌。
就現(xiàn)階段而言,傳統(tǒng)芯片廠商的CPU、GPU和DSP,其本質(zhì)上也是對(duì)現(xiàn)有的技術(shù)進(jìn)行微調(diào)。然而,由于傳統(tǒng)CPU、GPU和DSP本質(zhì)上并非以硬件神經(jīng)元和突觸為基本處理單元,相對(duì)于NPU在深度學(xué)習(xí)方面天生會(huì)有一定劣勢(shì),在芯片集成度和制造工藝水平相當(dāng)?shù)那闆r下,其表現(xiàn)必然遜色于NPU。
在NPU領(lǐng)域,由于IBM點(diǎn)歪了科技樹(shù),以及中科院在該領(lǐng)域具有前瞻性的開(kāi)展了一系列科研工作,使中國(guó)能在目前處于優(yōu)勢(shì)地位。至于中國(guó)和美國(guó)的深度學(xué)習(xí)處理器,哪一款產(chǎn)品能在商業(yè)上取得成功,則很大程度上取決于技術(shù)以外的因素。就現(xiàn)在情況來(lái)看,大家基本處于同一起跑線,鹿死誰(shuí)手,還未可知。
NPU中美競(jìng)賽 美國(guó)走歪了?
圖文簡(jiǎn)介
隨著人工智能和深度學(xué)習(xí)逐漸進(jìn)入人們視野,中科院、谷歌、IBM、英偉達(dá)等中......
- 來(lái)源: 科普融合創(chuàng)作與傳播
- 上傳時(shí)間:2016-10-12
