
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 科普中國創作培育計劃
科普中國創作培育計劃 
全球有超過2.5億視障人士,中國的這一數字達到1700萬。在城市的大街小巷,視障人士們依靠白手杖探路,卻只能感知腳下約一米范圍的地面,人行道上雜亂停放的共享單車、突然竄出的行人、地鐵站復雜的入口不亞于荊棘遍布。而頭頂的樹枝、胸前的欄桿、側面駛來的電動車,這些危險更是在白手杖的盲區。近年來,科技界不斷嘗試用新技術改善這一困境。智能手杖通過超聲波傳感器擴展了探測范圍,但仍局限于前方狹窄的扇形區域;GPS導航應用如Soundscape提供語音導航,卻無法識別臨時障礙物,在室內和高樓林立的城市中定位精度大打折扣;BeMyEyes等視頻協助應用依賴志愿者的實時幫助,但需要穩定的網絡和他人的時間配合。即便是被認為是最可靠的導盲方式,訓練有素的導盲犬,全國也僅有400多只服役,培訓周期長達2年,成本超過20萬元。
這些傳統和半智能化輔助工具的局限性,讓大多數視障者的活動范圍被嚴重壓縮,讓大多數視障者的活動范圍被嚴重壓縮。
2025年4月,上海交通大學的研究團隊在國際頂級期刊發表了一項研究成果:一套將視覺信息實時轉換為聽覺和觸覺反饋的AI導航系統。這套系統將視覺世界翻譯成視障者更容易理解的聲音提示和觸覺震動,構建起一張動態的感官導航地圖,讓視障人士通過聽和摸來感知原本需要看見的世界。
這套被稱為多模態可穿戴視覺輔助系統的設備,外觀上并不復雜:一副重約195克的智能眼鏡、一對輕巧的智能手環,以及一個骨傳導耳機。

要理解這套AI導航系統如何工作,我們首先需要理解一個基本問題:視覺信息的本質是什么?
當我們看到前方有一張桌子時,大腦實際上在處理什么信息?是桌子的顏色、形狀、大小,更重要的是它的空間位置:距離我們多遠、在哪個方向、占據多大空間。對于導航來說,這些空間信息才是關鍵。
研究團隊正是抓住了這一點。他們沒有試圖讓視障人士看見完整的視覺世界,而是提取出導航所需的核心空間信息,然后用聽覺和觸覺重新編碼。這套系統的眼睛是一個RGB-D深度相機。RGB我們都熟悉,就是相機拍攝的彩色照片。那個D代表Depth(深度),是整個系統的關鍵。
深度相機是如何測量距離的?它使用了一種巧妙的方法:結構光。可以想象這樣一個場景:在完全黑暗的房間里,拿著手電筒照射墻壁。如果墻壁是平的,光斑是圓形的;如果墻壁是斜的或者凹凸不平的,光斑就會變形。通過分析光斑的形變,你就能推斷出墻壁的形狀和距離。
深度相機的原理類似,光點打到物體上會產生不同程度的變形。相機內部的傳感器捕捉這些變形,通過復雜的計算,最終得出每個點的精確距離。而在深度圖上,每個像素不再代表顏色,而是代表距離。通常用顏色來表示:暖色代表近,冷色代表遠。
但這只是原始數據。
在日常行走中,我們的大腦在不斷處理兩類信息:識別(這是什么)和規劃(該怎么走)。AI系統也必須完成這兩個任務。
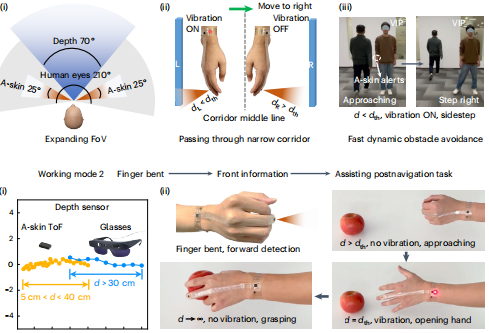
第一個任務是識別物體。系統使用了YOLOv8n神經網絡,專門優化到只識別21類最關鍵的物體。這里有個細節很有意思:研究團隊發現,導航時最大的挑戰不是物體識別不準,而是識別角度的局限。視障人士往往保持頭部朝前,導致很多危險來自視野邊緣。因此,系統特別強化了全方位檢測:無論椅子出現在正前方還是側面150度,都能保持相同的識別率。
而第二個任務,判斷哪里能走,才是真正的技術難點。
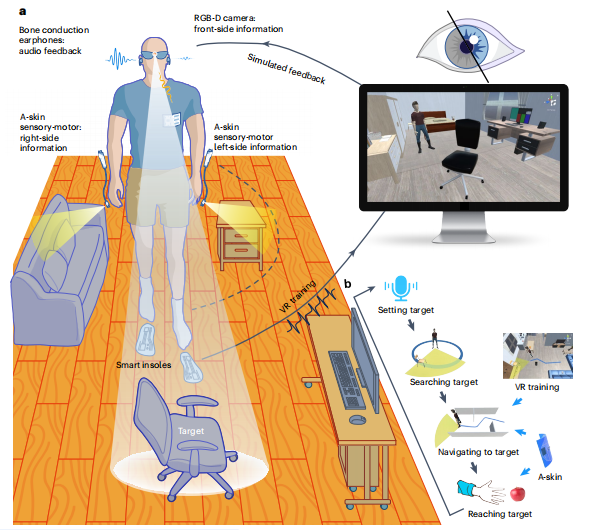
研究團隊最初嘗試用全局閾值法,設定一個距離閾值,比如3米內的所有物體都算障礙物。這對檢測高處的障礙物很有效。但當用戶低頭看路時,相機隨之下傾,3米的檢測范圍會投射到地面上,把正常地面也識別成障礙物。而如果把閾值設置得太小,又會漏掉遠處地面上的低矮障礙物,比如一塊磚頭、一個淺坑就可能會成為漏網之魚。
研究團隊意識到,在深度圖像中,正常的平坦地面有一個數學規律。站在一條筆直的道路上向前看,近處的地面在視野的下方,遠處的地面逐漸升高到地平線。這種升高遵循一個可預測的曲線。系統會實時計算這條理想地面曲線。任何偏離這條曲線的點都可能是障礙:高于曲線的點?可能是凸起的石塊或臺階。低于曲線的點?可能是凹陷的坑洞。曲線突然斷裂?可能是路緣或墻壁。
這種方法能自適應不同情況:無論是仰頭還是低頭,是走上坡還是下坡,系統都能動態調整理想曲線,確保檢測的準確性。
于是最終方案是讓兩種方法各司其職:
全局閾值法負責天空區域,專門捕捉懸空的危險
地面間隔法負責地面區域,不放過任何絆腳石。
在實際測試中,這種雙重保護將障礙物檢測率提升到了95%。通過這兩個算法的配合,系統實現了從地面到頭頂的立體防護網。整個檢測過程在200毫秒內完成,這個響應可比眨眼還快。
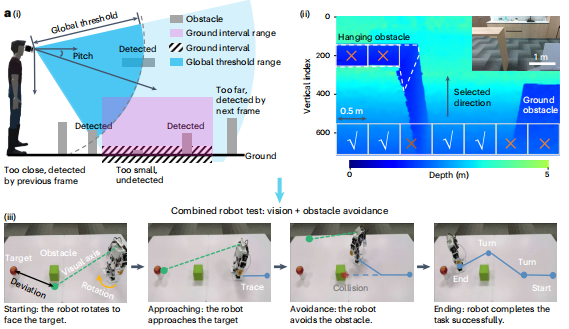
但這只是第一步,接下來的挑戰是:如何把這些復雜的空間信息,轉化成視障人士能夠直觀理解的信號?
把視覺信息轉換成聲音,這個想法并不新鮮。早在1960年代,就有人嘗試把圖像轉換成不同音調的聲音。但這些早期嘗試都失敗了,原因很簡單:信息超載。如果把眼前的每個物體都變成一種聲音,幾十種聲音同時響起,結果只會是一片噪音。
研究團隊采用了完全不同的思路:不是翻譯所有信息,而是只傳遞最關鍵的導航指令。研究團隊對比了空間化提示音、3D環境音和語言指令三種方式,結果是最簡單的提示音效果最好,平均定位誤差只有5度。語言指令雖然信息量大,但需要大腦先理解詞義再轉化為行動,這個過程需要500毫秒以上。而空間化提示音幾乎不需要思考,它順應了大腦處理聲音的自然方式,幾乎是本能反應。
但聲音有個致命弱點:它是線性的,同一時間只能傳遞一條信息。當左右兩邊同時有危險時怎么辦?這時候就需要觸覺了。
智能手環會當側面障礙物距離小于設定閾值時,相應一側的手環就會振動提醒。左邊有障礙,左手環振動;右邊有障礙,右手環振動。使用者可以根據自己的需求設定觸發距離。于是。聽覺負責告訴往哪走,觸覺警告離障礙物有多近;前方信息歸聽覺管,兩側信息歸觸覺管,兩種信號互不干擾。
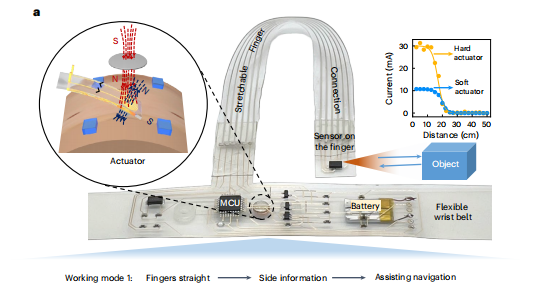
但只有前方和兩側的檢測還不夠。視障人士的日常生活不只是行走,還包括大量的手部操作,拿起桌上的水杯、按電梯按鈕、在超市貨架上尋找商品。因此智能手環被賦予了雙重身份。當手臂自然下垂時,手環朝向側面,監測行走時的側向威脅。而當抬起手臂伸向前方時,手環自動切換模式,變成精確的測距儀。它能告訴使用者手離目標還有多遠,什么時候該張開手掌準備抓取。而且系統采用紅外深度感知技術,即使在完全黑暗的環境中,系統的性能也絲毫不受影響。
隨著AI的技術愈發發達,采用專用AI芯片替代通用處理器可以將功耗降低,仿生視覺傳感器的應用也能夠進一步提升檢測精度,大規模生產會顯著降低成本。從更廣闊的視角看,這不僅是一項助盲技術。當AI能夠實時理解環境并轉化為多模態信號時,我們可以相信,它可以幫助更多人,例如老年人防跌倒、司機盲區預警、暗環境作業導航。
20名視障測試者給這套系統打出了79.6分的可用性評分,在5000個同類評測中排名前15%。但比分數更重要的,是他們重新獲得的可能性。正如研究團隊在論文結尾寫道:“這項工作為用戶友好的視覺輔助系統鋪平了道路,為視障人士提高生活質量提供了新的途徑。”
參考文獻
Tang, J., Zhu, Y., Jiang, G. et al. Human-centred design and fabrication of a wearable multimodal visual assistance system. Nat Mach Intell 7, 627–638 (2025).
來源: 科普中國創作培育計劃
內容資源由項目單位提供
