
 科普中國(guó)公眾號(hào)
科普中國(guó)公眾號(hào)
 科普中國(guó)微博
科普中國(guó)微博

 幫助
幫助
 重慶市科學(xué)技術(shù)協(xié)會(huì)
重慶市科學(xué)技術(shù)協(xié)會(huì) 
DeepSeek的火爆極大促進(jìn)了大語(yǔ)言模型在千行百業(yè)的落地。
首先是有了使用的信心。DeepSeek-R1推理模型已經(jīng)擁有6710億參數(shù)規(guī)模,符合“參數(shù)越多越智能”的認(rèn)知,而且有實(shí)際測(cè)試表現(xiàn)和廣泛的使用反饋?zhàn)鳛樽糇C,讓大家相信這個(gè)開源模型已經(jīng)足夠好了。其次是完全開源,不論是直接使用,還是用作基礎(chǔ)模型進(jìn)一步微調(diào)、后訓(xùn)練,都沒(méi)有法律風(fēng)險(xiǎn)。其三是豐儉由人,提供了671B全量模型,以及覆蓋70B、32B、7B等不同規(guī)模的蒸餾模型,還有若干低秩量化版本,可以滿足不同推理質(zhì)量和算力資源的要求。
【模型開源,獨(dú)享更香】
應(yīng)用的熱情盤活了大大小小云廠商的算力資源,隨著公開的DeepSeek服務(wù)紛紛癱瘓,連付費(fèi)客戶都大受影響。公有云“掉鏈子”引發(fā)的群體焦慮進(jìn)一步催生了私有化部署的熱潮:云廠商積極打包算力和服務(wù),主打低門檻和彈性;硬件廠商紛紛推出各式“推理一體機(jī)”,開箱即用。
自持資源的可及性、可靠性是私有化部署的重要原因,但更長(zhǎng)遠(yuǎn)地看,根本原因還是數(shù)據(jù)隱私與法規(guī)的要求。姑且不說(shuō)公有云服務(wù)商在用戶協(xié)議中的霸王條款,即使是私有云也會(huì)面臨數(shù)據(jù)上傳外網(wǎng)的合規(guī)限制。
利用大模型審查商業(yè)合同、法律文書,對(duì)病歷、科研數(shù)據(jù)進(jìn)行總結(jié),都能明顯節(jié)省時(shí)間,但恰恰都面臨隱私和法律風(fēng)險(xiǎn)。對(duì)于這類需求,在本地部署DeepSeek推理一體機(jī)是一個(gè)很好的選擇,而且,門檻并不高。
基于英特爾? 至強(qiáng)? W處理器、2~4塊GPU卡構(gòu)建的推理一體機(jī),預(yù)算在十萬(wàn)元左右,便可以支持?jǐn)?shù)十人并發(fā)使用的需求,滿足中小型企業(yè)全員上AI的需求。
【如何構(gòu)建高性價(jià)比算力底座】
英特爾? 至強(qiáng)? W是單路處理器,采用全大核、大緩存的架構(gòu),可以提供多達(dá)60核、112.5MB L3緩存(W9-3595X),睿頻加速可達(dá)4.8GHz,甚至部分后綴為X的型號(hào)還可以進(jìn)一步超頻。
對(duì)于推理一體機(jī),至強(qiáng)W的高擴(kuò)展性得到了充分發(fā)揮。它支持8通道內(nèi)存,內(nèi)存容量可以達(dá)到4TB;112條PCIe 5.0通道,可以配置4到7塊高性能GPU卡,不但可以加載較大參數(shù)規(guī)模的模型,還可以提供可擴(kuò)展的吞吐量。
以搭配英特爾? Arc? A770 16GB卡為例,單卡已經(jīng)可以部署7~14B蒸餾模型;雙卡可以部署32B蒸餾模型;4卡即可使32B蒸餾模型的推理輸出達(dá)到500~800 Tokens/s的水平。在中文環(huán)境下,每個(gè)Token相當(dāng)于0.75~1.8個(gè)漢字。以500Tokens/s、每Token對(duì)應(yīng)1個(gè)漢字計(jì),這就相當(dāng)于每分鐘輸出3萬(wàn)漢字。這個(gè)輸出能力足夠滿足20到50人的并發(fā)請(qǐng)求。
這里以部署DeepSeek-R1-32B為目標(biāo),是因?yàn)檫@個(gè)規(guī)模的蒸餾模型已經(jīng)在多數(shù)測(cè)試項(xiàng)目中超過(guò)了OpenAI-o1-mini,在實(shí)踐中也證明可以比較高質(zhì)量地完成長(zhǎng)文本處理、代碼生成等任務(wù)。以審查合同、會(huì)議紀(jì)要為代表的嚴(yán)肅工作可以交由部署32B大模型的一體機(jī)完成,而不再需要擔(dān)心隱私泄露甚至違法的風(fēng)險(xiǎn)。
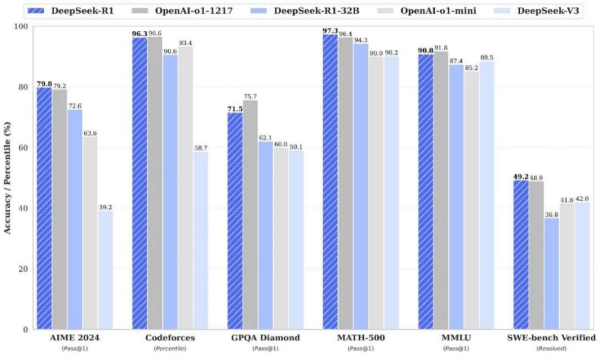
如果搭配24GB顯存的加速卡,還可以部署70B蒸餾模型,吞吐量以千計(jì),部分顯存位寬較大的卡可以達(dá)到2000Tokens/s以上,完全能夠滿足百人量級(jí)的同時(shí)使用需求。70B模型可以完成長(zhǎng)文本生成、創(chuàng)意輔助等高質(zhì)量的工作。另外,較大的顯存容量除了可以部署一個(gè)較大規(guī)模的模型,也可以實(shí)現(xiàn)在一體機(jī)內(nèi)部署多個(gè)不同規(guī)模、不同特點(diǎn)的中小型模型,以滿足不同類型用戶的需求。
值得一提的是,借助KTransformer為代表的開源大語(yǔ)言模型推理優(yōu)化框架,基于至強(qiáng)W的推理一體機(jī)還可以運(yùn)行“滿血版”的DeepSeek-R1,以支持對(duì)推理精度要求最高的任務(wù)。這類優(yōu)化框架可以讓GPU和CPU共同分擔(dān)計(jì)算任務(wù),并將一部分模型參數(shù)放置在容量較大的主內(nèi)存。以使用單條96GB DDR5 RDIMM為例,至強(qiáng)W的八個(gè)內(nèi)存通道可以實(shí)現(xiàn)768GB的內(nèi)存容量和307GB/s的內(nèi)存帶寬,獨(dú)立部署FP8精度的DeepSeek-R1 671B完全沒(méi)有問(wèn)題,更不用說(shuō)Q4、Q2量化版本了。
隨著KTransformer這類優(yōu)化框架的不斷開發(fā),還有機(jī)會(huì)進(jìn)一步發(fā)揮至強(qiáng)W內(nèi)置的AMX(Advanced Matrix Extension)加速器的優(yōu)勢(shì),進(jìn)一步提升推理吞吐量。至強(qiáng)? W-2400/3400正式開始引入AMX,可以每個(gè)時(shí)鐘周期內(nèi)進(jìn)行2048次并行運(yùn)算,在神經(jīng)網(wǎng)絡(luò)推理、機(jī)器學(xué)習(xí)當(dāng)中已經(jīng)展現(xiàn)了不錯(cuò)的實(shí)用性。
供稿單位:重慶天極網(wǎng)絡(luò)有限公司
審核專家:李志高
聲明:除原創(chuàng)內(nèi)容及特別說(shuō)明之外,部分圖片來(lái)源網(wǎng)絡(luò),非商業(yè)用途,僅作為科普傳播素材,版權(quán)歸原作者所有,若有侵權(quán),請(qǐng)聯(lián)系刪除。

來(lái)源: 重慶市科學(xué)技術(shù)協(xié)會(huì)
內(nèi)容資源由項(xiàng)目單位提供
