
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 科普中國創(chuàng)作培育計劃
科普中國創(chuàng)作培育計劃 
相信不少朋友已經(jīng)體驗(yàn)過文生圖這類模型,比如 MidJourney、Stable Diffusion 或 OpenAI 的 DALL·E 等。只需簡單輸入一段文字,就能獲得高質(zhì)量的圖像,這也讓許多平面設(shè)計師倍感壓力。接下來,我們將深入探討這類模型的工作原理。乍一聽似乎很復(fù)雜,但其實(shí)基本概念相當(dāng)直觀。
主流的文生圖模型大多采用了一種名為“擴(kuò)散”(Diffusion)的技術(shù)。擴(kuò)散的概念源自物理學(xué)領(lǐng)域,可以這樣理解:想象一杯清水,當(dāng)一滴墨水滴入水中時,墨水會逐漸與水混合,最終使得整杯水變色。這個過程中,墨水分子與水分子均勻混合,正是擴(kuò)散現(xiàn)象的體現(xiàn)。文生圖模型的核心思想正是基于這樣的擴(kuò)散過程。

以一張小貓的圖片為例。首先,我們可以通過向圖片中添加隨機(jī)像素(即噪點(diǎn)),使其變得模糊不清。隨著噪點(diǎn)數(shù)量的增加,圖片將逐漸失去原有的細(xì)節(jié),最終呈現(xiàn)出類似電視信號不佳時出現(xiàn)的雪花狀畫面。這種完全隨機(jī)的像素分布被稱為“白噪聲”。
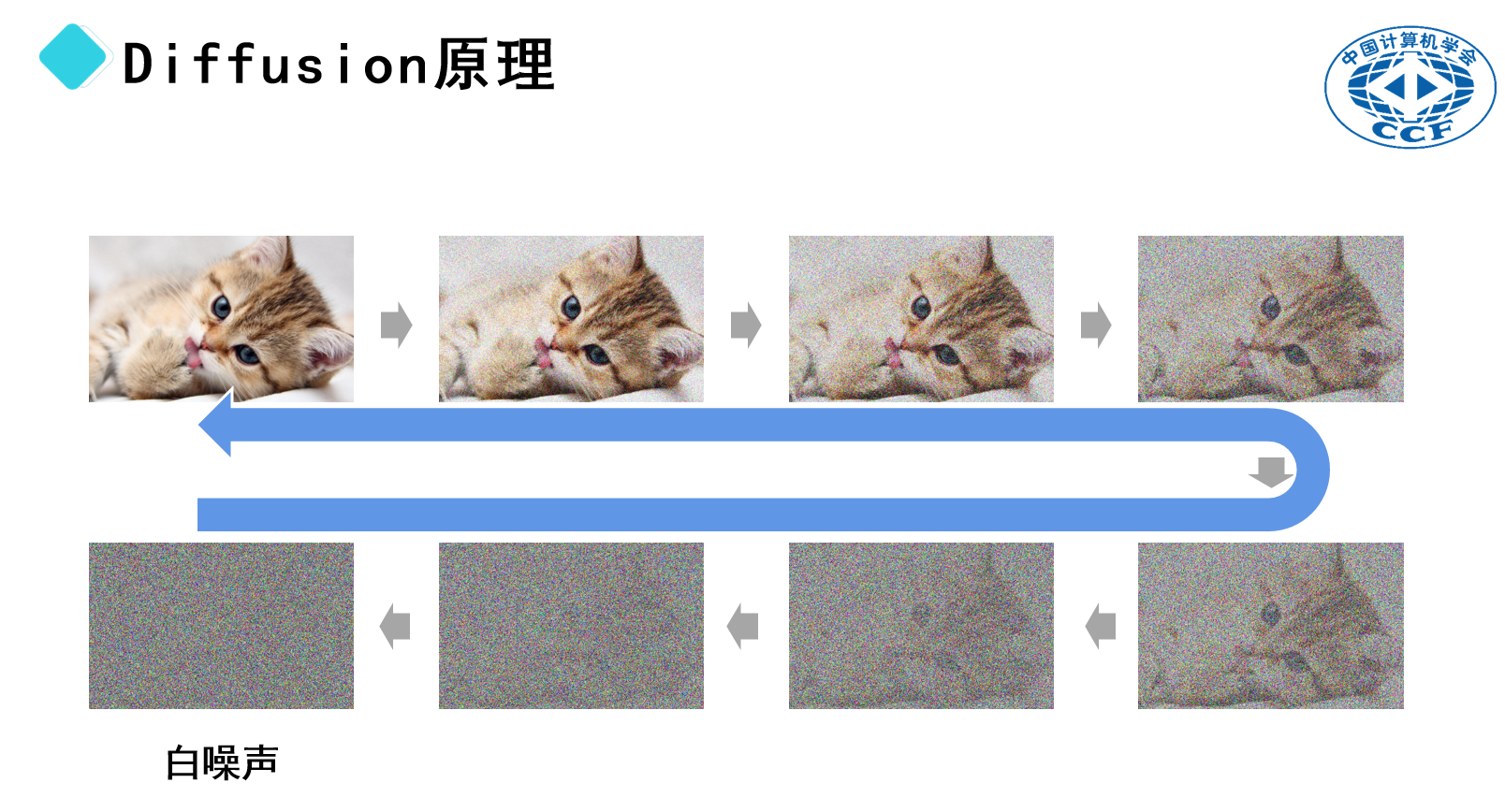
假設(shè)上述過程是可逆的,即我們可以從白噪聲開始,逐步去除噪點(diǎn),使原本模糊的畫面逐漸恢復(fù)清晰。在這個過程中,隱藏在白噪聲中的圖像逐漸浮現(xiàn),就像是小貓的輪廓逐漸顯現(xiàn)一樣。因此,文生圖模型的擴(kuò)散過程實(shí)際上是一種逆向操作——即“去噪”。
不過,這里還有一個問題:我們?nèi)绾螌⑽谋拘畔⑷谌脒@一過程中?答案將在后續(xù)的解釋中揭曉。
讓我們回到剛才討論的去噪過程。假設(shè)我們現(xiàn)在要訓(xùn)練一個大模型,我們可以暫且稱其為“圖像生成器”。該模型的功能是從含噪圖像中移除噪聲,從而生成清晰的圖像。具體來說,模型中的藍(lán)色部分負(fù)責(zé)實(shí)現(xiàn)從含噪圖像到清晰圖像的轉(zhuǎn)換。

但這只是開始。為了使模型能夠根據(jù)文本描述生成相應(yīng)的圖像,我們需要賦予它文本理解的能力。因此,我們需要另一個模型來實(shí)現(xiàn)這一點(diǎn)。這個模型將通過大量的帶注釋圖像進(jìn)行訓(xùn)練——每張圖像都配有一段描述性的文本。
 例如,一張“小狗在草地上奔跑”的圖片會配上相應(yīng)的文字描述。通過訓(xùn)練,模型將學(xué)會理解文本與圖像之間的關(guān)聯(lián)。
例如,一張“小狗在草地上奔跑”的圖片會配上相應(yīng)的文字描述。通過訓(xùn)練,模型將學(xué)會理解文本與圖像之間的關(guān)聯(lián)。
簡單來說,當(dāng)模型接收到“一只躺著的貓”這樣的文本輸入時,它會在其內(nèi)部生成與之匹配的圖像,而不會生成不相關(guān)的圖像,比如“在草地上奔跑的小狗”。
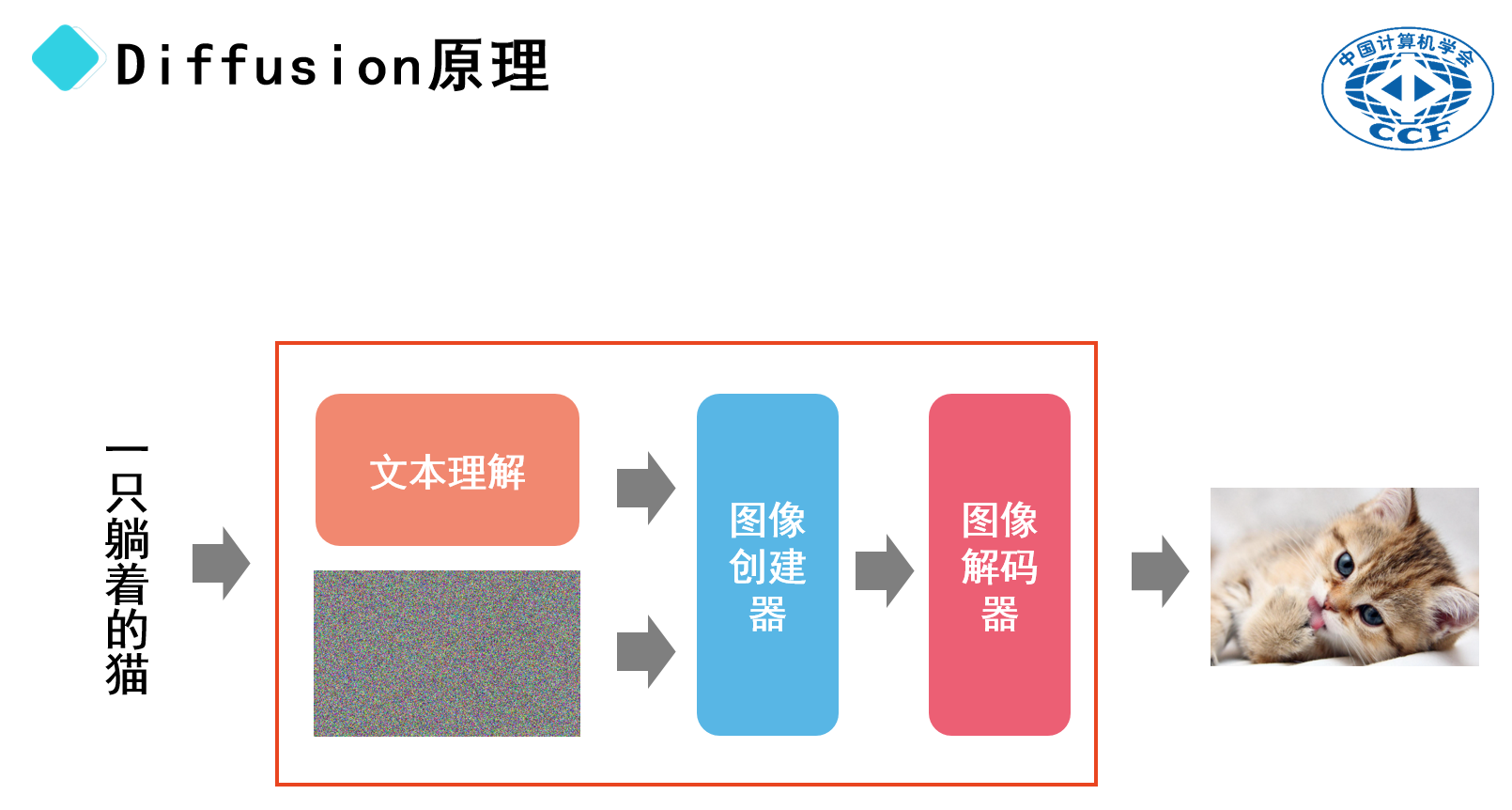
最終形成的“文本轉(zhuǎn)圖像”(Text-to-Image)模型包含了多個子模型。具體來說,模型首先需要具備文本理解能力,然后接收一個初始的含噪圖像作為“畫布”。接下來,模型中的“去噪”部分(即圖像生成器)根據(jù)文本內(nèi)容移除噪聲。最后,生成的圖像數(shù)據(jù)通過圖像解碼器轉(zhuǎn)換成可視化的圖像。
通過這種方式,模型可以根據(jù)提供的文本描述生成相應(yīng)的圖像,無論是山水畫還是小貓。這個過程類似于在一張充滿隨機(jī)噪聲的畫布上,根據(jù)給定的文字描述逐步去除噪聲,最終呈現(xiàn)出清晰的圖像。
同樣的原理也可以應(yīng)用于視頻生成。視頻本質(zhì)上是由一系列連續(xù)的靜態(tài)圖像組成,快速播放時給人以動態(tài)的感覺。因此,生成視頻的過程類似于連續(xù)生成多個靜態(tài)圖像,并將它們組合在一起形成連續(xù)的畫面。在這個過程中,同樣會用到diffusion技術(shù)。
幾個月前SORA大模型出現(xiàn)后有人認(rèn)為,SORA已經(jīng)能夠理解物理世界,通用人工智能(AGI)將在一兩年內(nèi)實(shí)現(xiàn)。這種觀點(diǎn)往往出自一些知名人士或意見領(lǐng)袖。然而,面對這樣的說法,我們不能盲目跟風(fēng),而是要用批判性思維來進(jìn)行深入分析。

我們先來看看嬰兒是如何在短短幾個月內(nèi)學(xué)會理解物理世界的。嬰兒出生時就像一張白紙,但到八九個月大時,他們已經(jīng)掌握了基本的物理規(guī)則。例如,當(dāng)嬰兒看到物體違背了重力法則而懸浮時,他們會表現(xiàn)出明顯的驚訝,這意味著他們已經(jīng)理解了物體不應(yīng)無故懸浮的基本原則。
人類之所以能夠在短時間內(nèi)迅速學(xué)習(xí)這些知識,很大程度上歸功于我們擁有的多種感官——視覺、聽覺、嗅覺、觸覺和味覺。通過這些感官,我們可以全方位地感知周圍環(huán)境。舉個例子,當(dāng)一個嬰兒觸摸到裝有熱水的杯子時,他不僅能看到杯子,還能感受到水的溫度,并在燙手時立即縮回手。杯子落地摔碎時,他不僅能聽到聲音,還能看到碎片四散的場景。所有這些感官體驗(yàn)共同作用,促進(jìn)了大腦的發(fā)展,并幫助我們理解物理世界。
相比之下,當(dāng)前的SORA大模型,主要依靠大量的視頻數(shù)據(jù)進(jìn)行訓(xùn)練。這些模型僅具備視覺輸入,缺乏嗅覺、觸覺和味覺等其他感官信息。如果我們將這些模型與嬰兒進(jìn)行類比,那么可以想象,如果一個嬰兒被限制在一個透明箱子里,只能通過視覺來觀察世界,而無法使用其他感官,那么他將難以發(fā)展出全面的理解能力。因此,在目前的技術(shù)條件下,期望這些模型能夠像人類那樣理解物理世界顯然是不切實(shí)際的。
本文為科普中國·創(chuàng)作培育計劃扶持作品
作者:孫善明 中國計算機(jī)學(xué)會GESP技術(shù)委員會主席;中國計算機(jī)學(xué)會PTA技術(shù)委員會常委;中國計算機(jī)學(xué)會科普工委委員;中國計算機(jī)學(xué)會高級會員;CCF2024年度杰出演講者;中國電子教育學(xué)會青少年教育分會副秘書長;
審核:崔原豪 南方科技大學(xué)系統(tǒng)設(shè)計與智能制造學(xué)院副研究員
出品:中國科協(xié)科普部
監(jiān)制:中國科學(xué)技術(shù)出版社有限公司、北京中科星河文化傳媒有限公司
來源: 科普中國創(chuàng)作培育計劃
內(nèi)容資源由項目單位提供
