
 科普中國公眾號(hào)
科普中國公眾號(hào)
 科普中國微博
科普中國微博

 幫助
幫助
 浙江省科學(xué)技術(shù)協(xié)會(huì)
浙江省科學(xué)技術(shù)協(xié)會(huì) 
近日,杭州深度求索人工智能基礎(chǔ)技術(shù)研究有限公司(以下簡稱“深度求索”)正式發(fā)布DeepSeek-R1模型。該模型號(hào)稱在數(shù)學(xué)、代碼、自然語言推理等任務(wù)上,性能比肩美國OpenAI公司最新的o1大模型正式版。
看到這一消息,你也許又懵了,DeepSeek-R1 和此前的DeepSeek-V3又有什么區(qū)別?簡單來說,R1是在V3的基礎(chǔ)上,又訓(xùn)練出的新模型。
Deepseek網(wǎng)頁截圖
“此次最大看點(diǎn)便是,DeepSeek-R1 后訓(xùn)練階段中,大規(guī)模使用了強(qiáng)化學(xué)習(xí)技術(shù),這一技術(shù)讓大模型學(xué)會(huì)了自己訓(xùn)練自己,就像秒殺的AlphaGo的AlphaZero一樣,通過自我博弈來進(jìn)化而不是通過人類的教導(dǎo)取得進(jìn)步。” 北京理工大學(xué)校外碩士生導(dǎo)師、無界AI聯(lián)合創(chuàng)始人馬千里說道。
通常情況下,一個(gè)大模型發(fā)布前,需要經(jīng)過層層訓(xùn)練,才會(huì)與大眾見面。在這過程中,大模型需要通過人工微調(diào),才能讓生成的內(nèi)容更準(zhǔn)確且符合預(yù)期。
“強(qiáng)化學(xué)習(xí)技術(shù)的使用,顛覆性地免去了模型啟動(dòng)前,需要人來監(jiān)督、微調(diào)的傳統(tǒng)認(rèn)知,真正意義上讓 AI 自己訓(xùn)練自己。”馬千里表示,這改變了OpenAI開創(chuàng)的大模型訓(xùn)練的“工業(yè)流程”,能夠極大減少人工和運(yùn)營的成本,走出了中國人自己特色的模型訓(xùn)練之路。
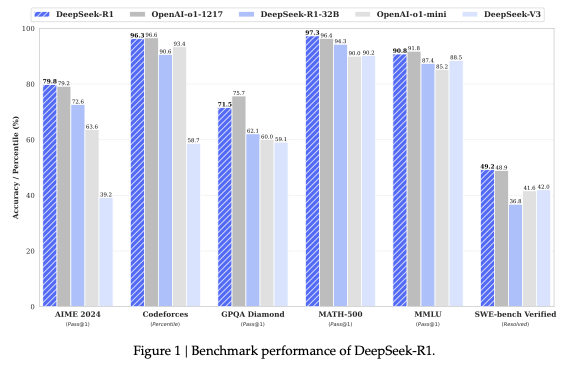
DeepSeek-R1在各項(xiàng)基準(zhǔn)評(píng)測集上的表現(xiàn),圖源:DeepSeek技術(shù)報(bào)告
除此之外,此次DeepSeek-R1還融合了“思維鏈”,在解決問題時(shí),會(huì)生成一系列中間推理步驟。
就像是解題時(shí),有人喜歡將每一步驟都詳盡地寫在卷子上,而 DeepSeek-R1更進(jìn)一步:把內(nèi)心 OS 也都寫出來了。“這樣的方式能夠較大程度減少大模型給出錯(cuò)誤或者虛幻的信息。”馬千里解釋道。
讓人驚訝的是,此次DeepSeek-R1 出現(xiàn)了“尤里卡時(shí)刻”(aha moment)——這一現(xiàn)象原指人類突然理解一個(gè)以前無法理解的問題或概念的某個(gè)時(shí)刻。
也就是說,模型在推理過程中會(huì)突然停下來說"等等", 然后自發(fā)地重新評(píng)估之前的步驟,并進(jìn)行反思,類似于人類的“靈光一現(xiàn)”。

Deepseek網(wǎng)頁截圖
當(dāng)記者輸入“三角形三邊長 3、4、5,求面積”后,DeepSeek-R1并不是直接反饋計(jì)算步驟,而是輸出了整個(gè)思考過程。仔細(xì)閱讀它的思考過程,語言風(fēng)格十分自然,還會(huì)說出“總之,我認(rèn)為這個(gè)三角形的面積是6,沒錯(cuò)”這樣“擬人”的表述,讓人感覺仿佛在與真人對(duì)話。
此外,深度求索還更新了用戶協(xié)議,明確模型開源License將統(tǒng)一使用標(biāo)準(zhǔn)的MIT許可。“這是較為徹底的開源協(xié)議,目前一些號(hào)稱‘開源’的大模型,實(shí)際上會(huì)有各種各樣的商業(yè)條款或?qū)@麠l款的限制。”馬千里表示,AI大模型可以看作為公共基礎(chǔ)設(shè)施,當(dāng)前需要更多像深度求索這樣開源的做法,從而促進(jìn)未來的發(fā)展。

圖源:社交平臺(tái)截圖
英偉達(dá)AI科學(xué)家Jim Fan稱贊DeepSeek是“真正開放的前沿研究,賦能所有人”。
(來源:潮新聞)
來源: 浙江省科學(xué)技術(shù)協(xié)會(huì)
