
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 中國自動化學會
中國自動化學會 導讀:2023年10月20-21日,以“智能涌現 生成未來”為主題的第二十五屆中國科協年會通用人工智能產業創新發展論壇在安徽省合肥市成功召開。中國科學院自動化研究所紫東太初大模型研究中心常務副主任、武漢人工智能研究院院長王金橋受邀出席并作題為“視覺大模型的實踐與思考”的主題報告。報告指出,隨著自監督學習的預訓練模型爆發式發展,以ChatGPT為代表的語言預訓練大模型取得了顯著進步,但視覺的多任務統一模型仍存在許多問題亟待解決。報告基于多任務統一學習的視覺自監督預訓練大模型學習機制和訓練方法,探索了自回歸和重建損失的聯合優化方法;提出面向通用物體分割的FastSAM的加速方法。
以下為報告全文。
ChatGPT推出以來,大語言模型技術的發展取得突破性發展。然而,人工智能應用的廣泛落地一直面臨著視覺通用性的關鍵挑戰。過去十年,人工智能廣泛應用的通用性難題長期存在。以前,我們側重于處理大數據、構建小模型、解決小任務,但這些模型的能力有限,主要的缺點在于依賴于大量標注數據、泛化能力差,難以適應不同場景。盡管目前技術上已經取得了一些突破,但人工智能落地應用仍然未能實現商業閉環。視覺與語言不同,實現通用的視覺能力尤為具有挑戰性,涉及到二維、三維、時間等多個維度的處理,需要解決復雜的設計、計算力、語言與視覺之間的對齊等問題。
一、視覺領域面臨的挑戰
人類的感知過程中,大約70%的信息是來自視覺。與語言不同,視覺信息是非結構化的,所以訓練視覺模型面臨著更大挑戰。如何實現視覺信息與語言單詞的對齊、如何激發多模態的涌現能力,都是亟待解決的復雜問題,如圖1所示。視覺信息涵蓋多個維度,包括對象的外觀、形狀、顏色、質地,以及與對象相關的場景和光照信息。此外,不同應用場景,如人臉識別、車輛識別等,需要構建不同的小模型,導致應用的碎片化。視覺問題還涉及長尾問題,與語言相比,視覺模型的部署成本相對較高。
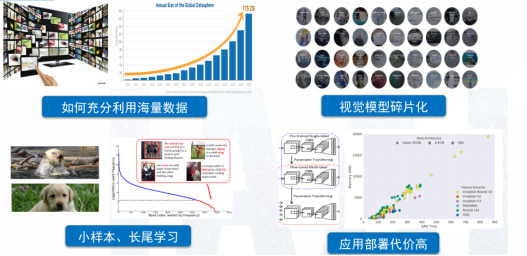
圖1 視覺領域計算方法面臨的挑戰
二、視覺大模型研究現狀
在視覺領域,自監督學習的應用一直備受關注,尤其是通過預測下一個單詞實現海量學習。國內外學者進行了廣泛的研究,包括比對學習、自回歸預測和掩碼預測等方法,如圖2所示。然而,視覺自監督學習仍面臨多個挑戰。由于視覺信息的多維性,需要考慮全局信息,同時也需要強調局部信息。不同的視覺任務涉及不同類型的信息,如檢測、分割、分類和回歸等,這增加了通用模型設計的復雜性。通用性和專用性之間存在一定矛盾,既要關注特定任務的識別,又要涵蓋全面的視覺知識來訓練視覺模型。多任務學習和通用模型設計是當前研究的重點,盡管現有模型的能力仍然有限,特別是在處理未知類別和自動標記方面存在挑戰。因此,解決這些問題需要更多的研究和技術創新,以實現更通用和高性能的視覺學習。
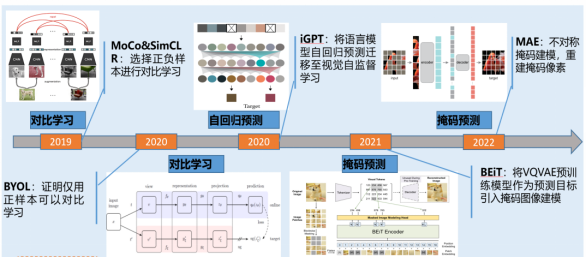
圖2 視覺自監督學習
2021年,隨著一系列視覺推理模型的涌現,如ViLD、M-DETR等,視覺自監督學習迎來迅速發展。與語言領域的大模型相比,視覺大模型在模型規模、訓練數據、多任務學習和智能涌現方面仍有較大差距。因此,國內外的研究機構和公司,如META、Google、華為、商湯等都在持續改進圖文融合模型。在圖文對話中,僅使用圖像對話往往信息量不夠,而圖文交錯結合的回答能提供更精準的信息和更豐富的體驗。此外,將文本模態與視頻和聲音相結合也會提供不同的感知和理解。因此,通用的純視覺模型仍需進一步的發展和完善。
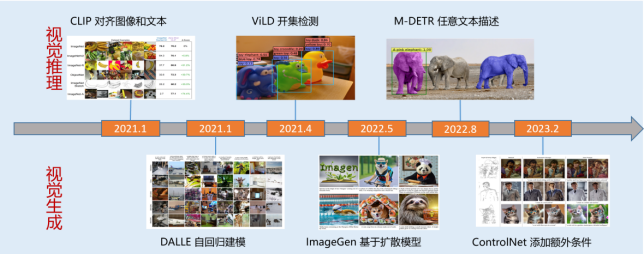
圖3 視覺推理與生成
三、視覺大模型的探索和實踐
中國科學院自動化研究所紫東太初大模型研究中心在視覺基礎模型領域進行了大量探索,自2020年起,成立了國內第一個大型模型研究中心。紫東太初大模型致力于構建全站自主可控的大型模型,以確保數據安全和隱私;其次,在視覺模型領域,持續探索視覺自監督學習的新路徑。引入可變形Transformer局部塊結構,它具有自適應預測每個局部塊的空間位置和大小的能力,如圖4所示。這意味著模型可以根據目標場景的結構和語義信息,靈活地預測每個模塊的大小,從而解決傳統固定大小滑塊在處理語義結構時的不完整性問題。這種可變形結構不僅有助于減少參數量,還能提高模型效率。
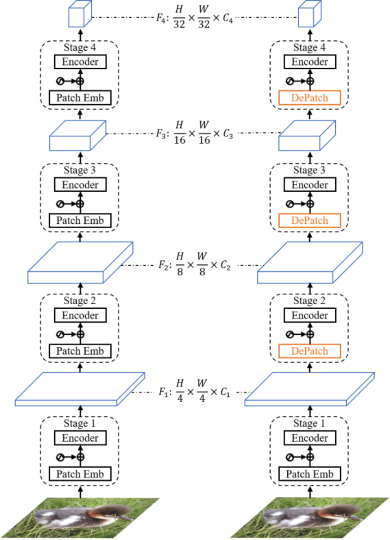
圖4 可形變視覺Transformer模型
此外,紫東太初大模型在視覺自監督學習領域作出新的嘗試,如將掩碼的重建與比對學習相結合。在研究時不僅關注掩碼的重建特性,還注重相似度和比對損失,通過構建動態的視覺掩碼機制,顯著提高了模型的收斂速度。這一模型相較于傳統的比對學習,其收斂速度通常能提高2-8倍,而且在大約100輪訓練后,即可達到主流效果的精度水平。
在圖像重構過程中,不僅考慮單一目標或場景,還要深入挖掘目標與場景、目標與區域之間的有效關系。這使得多層次和多粒度的自監督學習能夠實現,不再局限于單一目標的學習方式。該方法能在樣本數量僅占總樣本數1%-10%的情況下,超越傳統的自監督方法,同時不受特定場景的限制,增強模型通用性和語義特性。
在視覺自監督學習領域,紫東太初大模型提出了一些方法來應對隨機采樣可能導致的不均勻性問題。無論是掩碼重建還是自回歸方法,隨機采樣常常難以確保全面采樣和均勻分布。為了解決這一難題,紫東太初大模型引入了并行的掩碼機制,以確保采樣的數據相對均衡。另外,通過對損失函數進行優化,建立一致的預測損失,根據不同掩碼特性提高預測準確性,如圖5所示。這一優化將整個訓練的效率提高了6.65倍,并在性能方面也取得了顯著提升。通過以上創新方法,紫東太初大模型實現了視覺編碼與自監督訓練的對齊,并通過弱監督數據自適應地實現語言和數據的對齊,為多模態學習帶來了新的可能性。
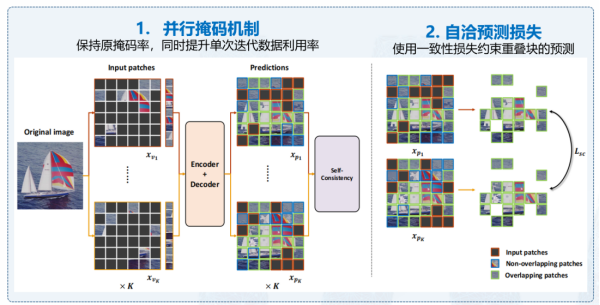
圖5 高效掩碼自洽模型
紫東太初大模型已成功建立了多模態環境下的多任務統一對齊機制,通過構建多任務自回歸預測結構,實現模型的一致性。該視覺多任務統一模型,通過圖像和語言編碼,能夠以多邊形形式統一表示各種任務,包括檢測、分割和關鍵點等。基于視覺知識的統一大型模型不再需要在不同場景下使用不同模型,而是能夠根據需要,輸出所需任務的結果。此外,紫東太初大模型還引入了基于視覺多任務的微調機制,使模型能夠根據指令輸出所需結果,無需構建多個不同的模型,還可以通過反饋學習來進一步完善意圖對齊和結果輸出。
四、視覺大模型應用
首先,紫東太初大模型可以自動識別海報中的內容,其次,可以進行知識進行推理。第三,可以進行工業場景自動定位目標應用。最后,模型還具備判斷能力,能夠識別圖像中的對象,例如可以判斷出“這不是一棵樹,而是一個穿著外套的男人”。
大模型還可以深入理解這些圖像中的情境和動作。在圖7中,人們在進行拍照活動,其中一名女性持手機在拍照,另一張圖中描述了一個人在挑選衣服,這些場景是與新零售相關的應用,大型模型能夠根據每個場景的需求提供長尾問題的解決能力。上述示例展示了大模型視覺模型具備的多種語義推理能力。
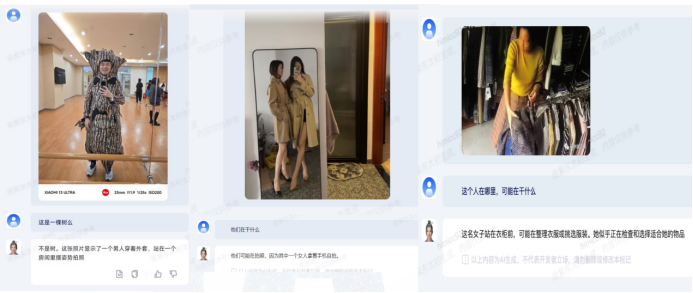
圖7 圖文理解/推理能力
除了通用模型,我們還研發了專門針對特定應用的模型,其中一個顯著的例子是FastSAM,如圖8所示,它是一個通用目標分割模型,性能比SAM高出50倍,在Hugging Face上177 like,Github已達5.8k stars。另一個重要應用是工業異常檢測,我們開發了通用工業檢測模型,適應于工業領域碎片化數據和有限樣本情況,能夠有效檢測任何文本描述的正常和異常情況,為工業環境帶來廣泛的應用前景。
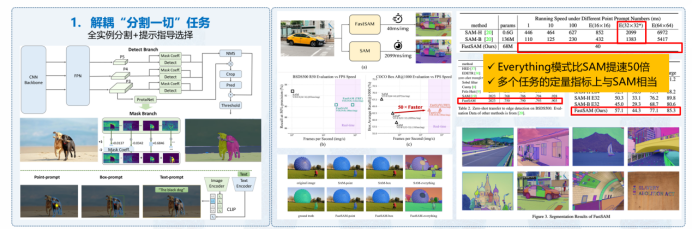
圖8 通用物體快速分割大模型:FastSAM
這些應用覆蓋了圖像級別的少樣本數據集,尤其在工業數據集方面,模型性能顯著提升。在碎片化場景中,例如高鐵的缺陷檢測,視覺大模型的初始化可以使基礎能力提高10%,再加入一些樣本后,精度可以提升30%。在開放式場景中,例如道路缺陷檢測,面對可能的各種障礙物,使用視覺大模型可提高巡檢精度10%,顯著降低30%的誤報率。
在醫療器械管理方面,原本需要人工操作的工作,現在通過大型模型,手術器械的準備時間可以從一個小時縮短至半個小時,培訓護工的時間也大大減少,工作效率提高了30倍,精度高達到99%。使用一個模型可以實現智能化的管理,僅需2臺服務器即可為10家醫院的所有手術提供管理服務。
最后,交通違章違法檢測也將受益于大模型的泛化能力。通過積累的違章數據,可以直接生成檢測模型,其精度基本能夠超過人工審核,目前已經在全國60多個省市區縣部署。以上示例突顯了視覺大模型在多個領域的廣泛應用。
盡管視覺大模型在通用能力上具有明顯優勢,但由于結合了視覺和語言,推理成本相對較高。未來,還需構建更高效的模型以及提升多場景能力以優化推理過程。此外,基于目前OCR和分割方面呈現出的強大潛力,未來還需繼續專注于通過指令實現更精確的理解和生成。我們已經推出多模態照片說話平臺,目前已對外開放,每個用戶都可以生成更加精準的個性化視頻內容。
最后,由于數據涉及敏感信息和語義信息,視覺大模型格外強調視覺數據的安全性和可控性。語義信息和內涵必須與價值觀和形態意識相一致,因此需更加關注數據的清洗和生成過程,以確保數據的安全性和可控性。
(本文根據作者論壇報告速記整理而成,經作者授權發布)
作者簡介:

王金橋,中國科學院自動化研究所紫東太初大模型研究中心常務副主任,研究員,博導,武漢人工智能研究院院長,中國科學院大學人工智能學院崗位教授,多模態人工智能產業聯盟秘書長,主要從事多模態大模型、視頻分析與檢索、大規模目標識別等方面的研究。共發表包括IEEE國際權威期刊和頂級會議論文300余篇,國際期刊50余篇,國際會議220余篇。完成國家標準提案3項,發明專利36項,10項國際視覺算法競賽冠軍,新時代中國經濟創新人物,北京市科技進步一等獎,世界人工智能大會SAIL獎,吳文俊人工智能科技進步二等獎,中國發明創新銀獎。
來源: 中國自動化學會
內容資源由項目單位提供
