
 科普中國(guó)公眾號(hào)
科普中國(guó)公眾號(hào)
 科普中國(guó)微博
科普中國(guó)微博

 幫助
幫助
 中啟行
中啟行 極簡(jiǎn)介紹大模型Transformer架構(gòu)選型
To be [decoder], or not to be [decoder], that is the question. -- William Shakespeare
Google 2017年《Attention Is All You Need》論文中提出Transformer模型,基于Encoder-Decoder架構(gòu)。

并在之后論文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中提出 BERT 模型,特點(diǎn)如下:
利用 Transformer 的 Encoder 架構(gòu);
預(yù)訓(xùn)練和 Fine-tuning;
預(yù)訓(xùn)練任務(wù)先在句中隨機(jī)掩碼幾個(gè)詞,后利用上下文預(yù)測(cè)這些詞,進(jìn)而預(yù)測(cè)下一句;
雙向,上文+下文;
BERT 一度空前流行,國(guó)內(nèi)很多公司的大模型都是基于Bert進(jìn)一步訓(xùn)練的。OpenAI 則默默堅(jiān)守GPT方向,直到ChatGPT 橫空出世。GPT 模型特點(diǎn)如下:
利用 Transformer 的 Decoder 架構(gòu);
預(yù)訓(xùn)練+Prompts(提示);
預(yù)訓(xùn)練任務(wù)先在句中掩碼最后一詞,后利用上文預(yù)測(cè)這個(gè)詞,把預(yù)測(cè)的這個(gè)詞用作上文,預(yù)測(cè)再下一個(gè)詞(自回歸);
單向,從左到右,僅上文;
兩者演化為如下的譜系:

兩者對(duì)應(yīng)的預(yù)訓(xùn)練的優(yōu)化目標(biāo)函數(shù)分別如下,我們先看GPT
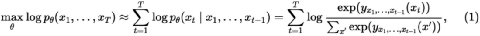
自回歸(AR: Auto Regression)在學(xué)什么?“上文”中每個(gè)詞與它們的組合的聯(lián)合概率最大。
AR 是在反復(fù)學(xué)習(xí)遣詞造句,語料是別人造好的句子,捂住最后面的,只看前面的,試著續(xù)寫出來整個(gè)句子。訓(xùn)練的是事前諸葛亮的能力,符合人類正常的思維方式。某種意義上,AR其實(shí)是對(duì)人類思維流機(jī)理的學(xué)習(xí)。
很多情況下,AR學(xué)到了不僅僅有概率,還有因果,仔細(xì)體會(huì):石頭打人很 [ ],預(yù)測(cè)得到“疼”。
回過頭再看 Bert,
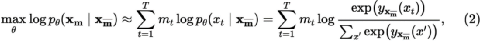
自編碼(AE:Auto Encoding)在學(xué)什么?“上文”加上“下文”中每個(gè)詞與它們的組合的聯(lián)合概率最大。
AE 是在反復(fù)學(xué)習(xí)完形填空,語料是整篇文章,隨機(jī)捂住中間的單詞,通過上下文猜出這些單詞。訓(xùn)練的是事后諸葛亮的能力,不符合人類正常思維方式。大家寫作文,常打個(gè)腹稿,下筆還是思維流的方式補(bǔ)全調(diào)整細(xì)節(jié)措辭,很少整篇文字一次性噴涌而出。
很多情況下,AE學(xué)到了完形填空的精髓,為了考試而考試的機(jī)巧,石頭 [ ] 人很疼,或許能預(yù)測(cè)出“打”字,但會(huì)更吃力,而且缺少泛化能力。
“事實(shí)證明,完型填空通常是同學(xué)們較難把握的題型之一,且失分率較高。”這是谷歌搜索完形填空第一條搜索結(jié)果。“托福雅思都沒有,表示這個(gè)已經(jīng)不適合語言學(xué)發(fā)展”,模型在針對(duì)這樣的題目訓(xùn)練,其實(shí)除了自虐,學(xué)不到多少機(jī)理。

籍此,筆者有一個(gè)可能讓不少人惱火的判斷,所有基于Bert的模型都因?yàn)槭褂昧薊ncoder而很難涌現(xiàn),反倒是僅用 Decoder的GPT 類的容易涌現(xiàn)。Google Bert and Bard 都是成本高昂的試錯(cuò),其技術(shù)成果與發(fā)現(xiàn),為GPT做了嫁衣裳。
AR 在學(xué)寫作的機(jī)理,機(jī)理學(xué)習(xí)多了,容易涌現(xiàn);而AE 將模型注意力放到了寫作的機(jī)巧,機(jī)巧學(xué)習(xí)多了,反而造成混亂。
來源: 中國(guó)科技新聞學(xué)會(huì)
