
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 HyperAI超神經
HyperAI超神經 
人與人交往中,說話表達是最基本的能力和方式,可世界上有很多人,卻「有口難言」。
「失語癥」中,由中風引起的最為常見。他們的聲音無法傳達,他們的訴求不為人所知,他們遭受著社交孤立,他們的沉默震耳欲聾。
每一個因中風而失語之人,無不渴望恢復完全、自然的交流能力,盡管目前全世界范圍內癱瘓無法根治,但如今在 AI 加持下,喪失說話能力的癱瘓患者也可以重新恢復聲音,并以豐富的表情、動作與人實時交流。
作者 | 鐵塔
編輯 | 三羊
本文首發于 HyperAI 超神經微信公眾平臺~
茨威格曾言,「一個人生命中最大的幸運,莫過于在他的人生中途,即他年富力強的時候發現了自己的使命。」
而人最大的不幸是什么呢?
在小編看來,一個人生命中最大的不幸,莫過于在風華正茂的年紀,突然喪失所有語言和行動能力——一夕之間,夢想、事業、愿望統統化為泡影,生活被整個掀翻。
Ann 就是其中不幸的代表。
三十而立,中風失語
2005 年某天,一向身體倍兒棒的 Ann 突然出現頭暈、吐字不清、四肢癱瘓和肌無力等癥狀,經診斷,她患上了腦干梗死(即我們日常所說的「中風」),伴有左椎動脈夾層和基底動脈閉塞。
這場毫無預兆的中風給 Ann 帶來了名為「閉鎖綜合征」的副產品——罹患此病者,所有感官意識俱在,但無法調動身體任何一塊肌肉,患者既不能活動,也不能自主說話,有的甚至無法呼吸。
正如「閉鎖」字面所體現的,帶領常人走遍千山萬水的身體,成了封印患者靈魂的牢籠。
彼時, Ann 才 30 歲,結婚 2 年零 2 個月,女兒剛出生 13 個月,在加拿大一所高中當數學老師。「一夜之間,我的一切都被奪走了。」 Ann 后來借助設備,在電腦上緩慢地敲下了這句話。

參與研究的 Ann
經過多年的物理治療, Ann 才可以呼吸、稍微轉動頭部、眨眨眼、說幾句話,但僅此而已。
要知道,正常生活中,一般人的講話語速在 160-200 字/分鐘之間,而 2007 年來自美國亞利桑那大學心理學系的研究結果顯示:男性平均每天要說 15,669 個單詞,女性平均要說 16,215 個單詞(平均一個單詞對應 1.5-2 個漢字)。
在語言是人際交流主要手段的世界里,可以想見,表達受限的 Ann 有多少需求被堙滅在無聲之中?伴隨失語而失去的,不僅僅是生活質量,乃至人格和身份。而全世界又有多少癱瘓失語者和 Ann 處于同樣的境地?
癱瘓18年,重新開口
恢復完全、自然的交流能力,是每一個因癱瘓而失語之人的最大渴望。在科技高度發達的今天,有沒有辦法借助技術的力量,將人際交流的能力還給患者?
有!
近期,來自美國加州大學舊金山分校和加州大學伯克利分校的研究團隊利用 AI 開發出一種新的腦機技術,讓失語 18 年的 Ann 重新「開口說話」,并基于數字化身產生生動的面部表情,幫助患者以符合正常人社交的速度和質量與他人實時交談。

Ann 借助數字化身與人交談
這是人類歷史上首次從大腦信號中合成語音和面部表情的創舉!
加州大學團隊此前的研究表明,從癱瘓者的大腦活動中解碼語言是可能的,但只能以文本的形式輸出,而且速度和詞匯量有限。
此番他們想更進一步:既能實現更快的大詞匯量文本交流,又能恢復與說話相關的語音和面部動作。
基于機器學習與腦機接口技術,研究團隊實現了以下成果,發表于 2023 年 8 月 23 日的《Nature》上:
? 對于文本,將受試者的腦信號以每分鐘 78 個單詞的速度解碼為文本,平均單詞錯誤率為 25%,比受試者當前使用的通信設備(14 個單詞/分鐘)快了 4 倍多;
?對于語音音頻,將腦信號快速合成為可理解和個性化的聲音,與受試者受傷前的聲音一致;
?對于面部數字化身,實現了語音和非語音交流手勢的虛擬面部運動控制。

論文鏈接:
https://www.nature.com/articles/s41586-023-06443-4
你一定很好奇,這種劃時代的奇跡怎么實現的?接下來,咱們具體拆解一下這篇論文,看研究人員如何妙手回春。
1.底層邏輯:腦信號→語音+面部表情
人類大腦通過外周神經和肌肉組織實現信息輸出,而語言能力由大腦皮質中的「語言中樞」所控制。
中風患者之所以失語,原因在于血液循環受阻,大腦語言區域因缺少氧氣和重要營養物質而受損,導致一個或多個語言溝通機制無法正常運作,從而出現語言功能障礙。
對此,加州大學舊金山分校和伯克利分校的研究團隊設計了一個「多模態語音神經假體」,使用大范圍、高密度的皮質腦電圖 (ECoG) 來解碼分布在整個感覺皮層 (SMC) 發音聲道表征的文本和視聽語音輸出,即從源頭上捕捉大腦信號,通過技術手段將其「翻譯」成對應的文本、語音甚至面部表情。
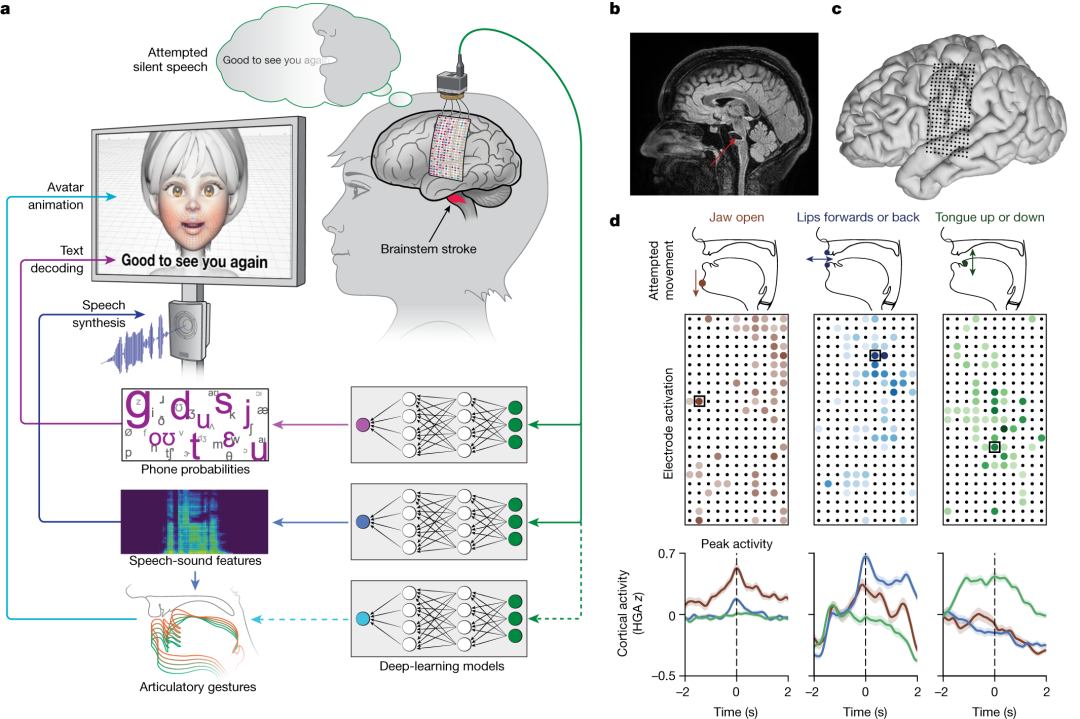
聲道癱瘓患者的多模態語音解碼
2.過程及實現:腦機接口 + AI 算法
首先是物理手段。
研究人員通過硬膜在 Ann 大腦左半球的腦頂表面植入了一個高密度腦電圖陣列和經皮底座連接器,覆蓋與語言產生和語言感知相關的區域。
該陣列由 253 個圓盤狀電極組成,用于攔截原本傳送到 Ann 舌頭、下巴、喉嚨及臉部肌肉的大腦信號。一根電纜插入固定在 Ann 頭上的端口,將電極與一組計算機相連。
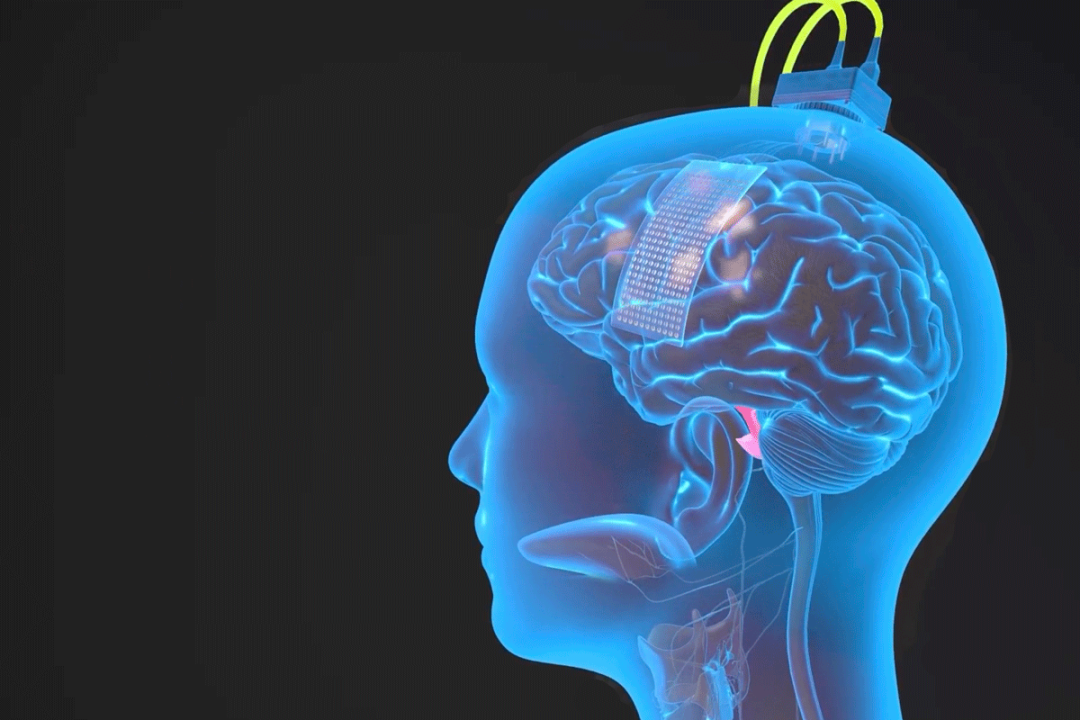
電極陣列植入受試者大腦皮層表面的語言控制區
其次是算法構建。
為識別 Ann 獨特的大腦語音信號,研究團隊與她一起花費了幾周時間來訓練和評估深度學習模型。
研究人員基于 nltk Twitter 語料庫和 Cornell 電影語料庫創建了 1,024 個單詞的通用句子集,指示 Ann 以自然語速無聲說話。她一遍又一遍地從1,024 個單詞的會話詞匯中默念不同的短語,直到計算機識別出與這些聲音相關的大腦活動模式。
值得注意的是,這個模型并非訓練 AI 識別整個單詞,而是創建了一個系統從「音素」中解碼單詞,如「Hello」包含四個音素:「HH」、「AH」、「L」和「OW」。
基于這種方法,計算機只需學習 39 個音素就能解讀任何英語單詞,既增進了準確性,又將速度提升了 3 倍。
注:音素是語言的最小聲音單位,可描述語音的發音特征,包括發音部位、發音方式和聲帶振動等,如 an 的音素由 /?/ 和 /n/ 組成。
這個音素解碼的過程,類似嬰兒學說話的過程。根據目前發展語言學界較為公認的觀點,剛出生的嬰兒就能分辨全世界語言中的 800 個音素。學齡前兒童可以不懂詞句的寫法與意思,但卻能通過對音素的感知、區分和模仿來逐漸學會發音和理解語言。
最后是語音和面部表情合成。
基礎已經打完,接下來是語音和面部表情的顯化呈現,研究人員通過語音合成和數字化身來解決這個問題。
語音方面,研究人員開發了一種合成語音算法,使用了 Ann 中風前的聲音錄音,盡可能使數字化身的聲音聽起來像她。
面部表情上, Ann 的數字化身由 Speech Graphics 公司開發的軟件創建而成,呈現為屏幕上的女性臉部動畫。
研究人員定制了機器學習過程,使軟件與 Ann 試圖說話時大腦發出的信號相協調,從而表現出下巴張開和閉合、嘴唇突出和收縮、舌頭上下運動,以及表達快樂、悲傷和驚訝的面部運動及手勢。

Ann 正與研究人員一起進行算法訓練
未來展望
加州大學舊金山分校神經外科主任、醫學博士 Edward Chang 表示,「 我們的目標是恢復一種完整的、具體的溝通方式,這是我們與他人交談最自然的方式……將可聽到的語言與真人化身結合起來的目標,能讓人類語言交流得到充分體現,而這遠遠不止語言。」
研究團隊的下一步是創建一個無線版本,擺脫腦機接口的物理連接,使癱瘓的人們能利用這項技術自如地控制個人手機和電腦,而這將對他們的獨立性和社會交往產生深遠影響。
從手機上的語音助手、電子刷臉支付到工廠里的機械臂、生產線上的分揀機器人,AI 正在延伸人類的四肢與五官,并逐漸滲透到我們生產生活的方方面面。
科研人員關注癱瘓失語者這一特殊群體,利用AI的力量幫助其恢復自然的交流能力,有望促進患者與親友之間的聯絡,擴大他們重新獲得人際互動的機會,并最終提高患者的生活質量。
我們為這一成就感到振奮,期待更多 AI 造福人類的捷報傳來。
參考鏈接:
[1] https://www.sciencedaily.com/releases/2023/08/230823122530.htm
[2] http://mrw.so/6nWwSB
本文首發于 HyperAI 超神經微信公眾平臺~
來源: HyperAI超神經
