
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 重慶市科學(xué)技術(shù)協(xié)會
重慶市科學(xué)技術(shù)協(xié)會 
北京時間8月8日凌晨1點(diǎn),OpenAI正式發(fā)布GPT-5。山姆·奧爾特曼(Sam Altman)稱GPT-5是“邁向通用人工智能(AGI)的重要一步”。他還表示,GPT-5就像是一位真正的博士級專家,精通任何你需要的領(lǐng)域。

然而發(fā)布會后大家對于GPT-5的評價直接兩極分化,有說超預(yù)期的,也有失望“就這?”的。為什么會這樣?我們先來看看GPT-5到底升級了啥?
編程、寫作、多模態(tài)、醫(yī)療咨詢?nèi)孢M(jìn)化
這場一個多小時的發(fā)布會,OpenAI的功能展示占據(jù)了絕大多數(shù)戲份。
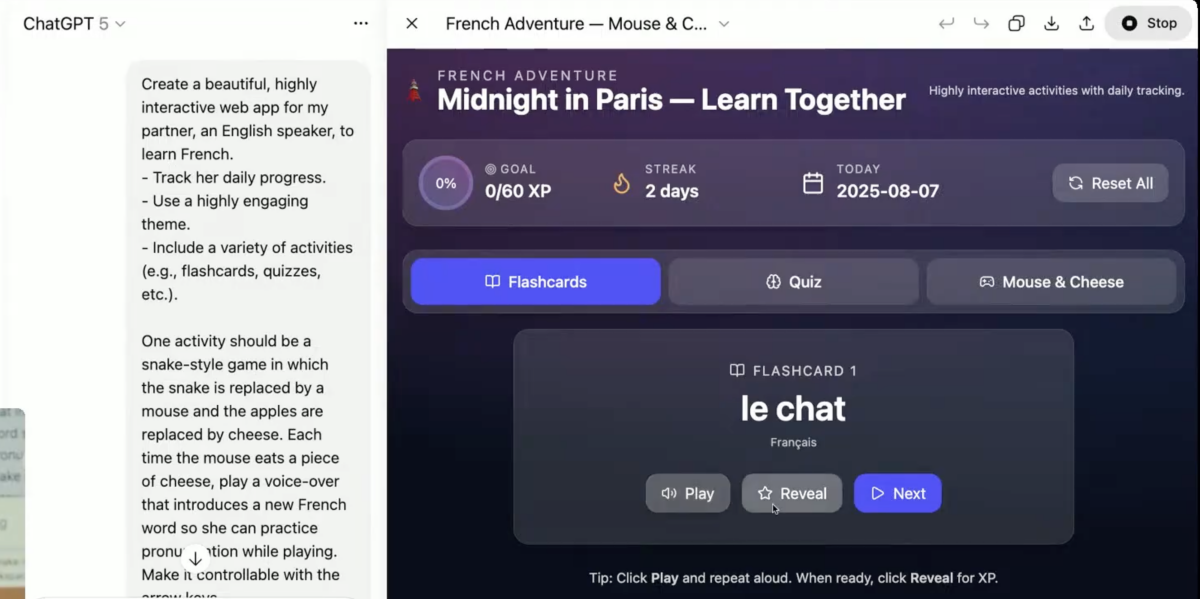
首先是編程能力,GPT-5直接刷新了行業(yè)天花板,在SWE-Bench Verified(代碼修復(fù)測試)中得分74.9%,在Aider Polyglot(多語言編程測試)中得分88%,遠(yuǎn)超前代模型。在發(fā)布會上,OpenAI后期訓(xùn)練負(fù)責(zé)人Yann Dubois現(xiàn)場演示了GPT-5如何根據(jù)指令快速生成法語學(xué)習(xí)、并帶有互動游戲的網(wǎng)站,甚至能自動處理交互設(shè)計、進(jìn)度記錄等功能。短短幾分鐘就有這樣精致的頁面,確實讓人驚艷。
多模態(tài)理解方面,GPT-5在一系列多模式基準(zhǔn)測試中表現(xiàn)出色,涵蓋視覺、基于視頻、空間和科學(xué)推理。更強(qiáng)的多模態(tài)性能意味著,可以更準(zhǔn)確地推理圖像和其他非文本輸入,無論是解釋圖表,總結(jié)演示文稿的照片還是回答有關(guān)圖表的問題。
寫作方面,OpenAI毫不謙虛地稱GPT-5為“GPT-5是迄今為止最強(qiáng)大的寫作協(xié)作工具”。該模型能夠幫助用戶將粗略的想法轉(zhuǎn)化為引人入勝、富有文學(xué)深度和節(jié)奏感的文字作品。
健康咨詢方面,在HealthBench Hard(醫(yī)療問答測試)中,GPT-5得分46.2%。OpenAI表示,與以前的模型相比,GPT-5更像是一個積極的思想伙伴,主動標(biāo)記潛在的問題并提出問題以提供更多有用的答案。OpenAI強(qiáng)調(diào),該模型還提供了更精確和可靠的響應(yīng),適應(yīng)用戶的上下文,知識水平和地理位置,使其能夠在廣泛的場景中提供更安全和更有用的響應(yīng)。

想象一下,將我們的體檢報告上傳交給AI來輔助判斷,或許能夠更好地、更及時地制定診療決策。發(fā)布會上,OpenAI也邀請了一位同時患有三種癌癥的女士分享了經(jīng)歷。這名換著通過上傳病例報告到ChatGPT,更好地理解了報告中專業(yè)的醫(yī)療術(shù)語,在確診初期對于自己面臨的情況有了更清晰的理解。甚至由于病情的復(fù)雜程度,當(dāng)專家把治療決定全交給這位女士時,她選擇了GPT來結(jié)合海量信息分析報告,并最終輔助這位患者做出了正確的決定。
除了以上升級外,GPT-5還在降低幻覺影響方面取得突破。在啟用網(wǎng)頁搜索時,GPT-5響應(yīng)的事實錯誤率較GPT-4o降低約45%;深度思考模式下,錯誤率較OpenAI o3降低近80%,大幅減少了“一本正經(jīng)胡說八道”的情況。更難得的是,GPT-5在嚴(yán)守事實的同時,指令遵循能力躍升,拍馬屁的傾向也大大降低。
為了讓對話更有趣,GPT-5還引入了批判者(Cynic)、分析者(Robot)、傾聽者(Listener)和書呆子(Nerd)四種“人格模式”供用戶選擇。比如讓模型以“書呆子”模式詳細(xì)解釋量子力學(xué)原理,或以“傾聽者”模式提供情感支持。
從免費(fèi)用戶到Pro套餐,API定價競爭力凸顯
OpenAI的商業(yè)化策略同樣值得關(guān)注。免費(fèi)用戶可直接使用GPT-5(普通版,帶推理功能),但每月使用額度有限,觸及上限后,系統(tǒng)會自動切換到GPT-5-mini(輕量型);Plus訂閱用戶除了能使用這些模型外,還享有更高的使用限額。而每月200美元的Pro套餐可無限使用GPT-5,并解鎖更強(qiáng)的GPT-5 Pro版本(適合處理復(fù)雜任務(wù))和GPT-5 Thinking(延長推理時間)。

對于開發(fā)者,OpenAI的API定價也頗具競爭力:GPT-5輸入1.25美元/百萬tokens,輸出10美元/百萬tokens;GPT-5 mini輸入0.25美元/百萬tokens,輸出2美元/百萬tokens;GPT-5 nano輸入0.05美元/百萬tokens,輸出0.4美元/百萬tokens。相較主要對手Anthropic與Google,GPT-5在不僅具備競爭力,甚至更為親民。
性能飛躍能否掩蓋PPT翻車與幻覺爭議?
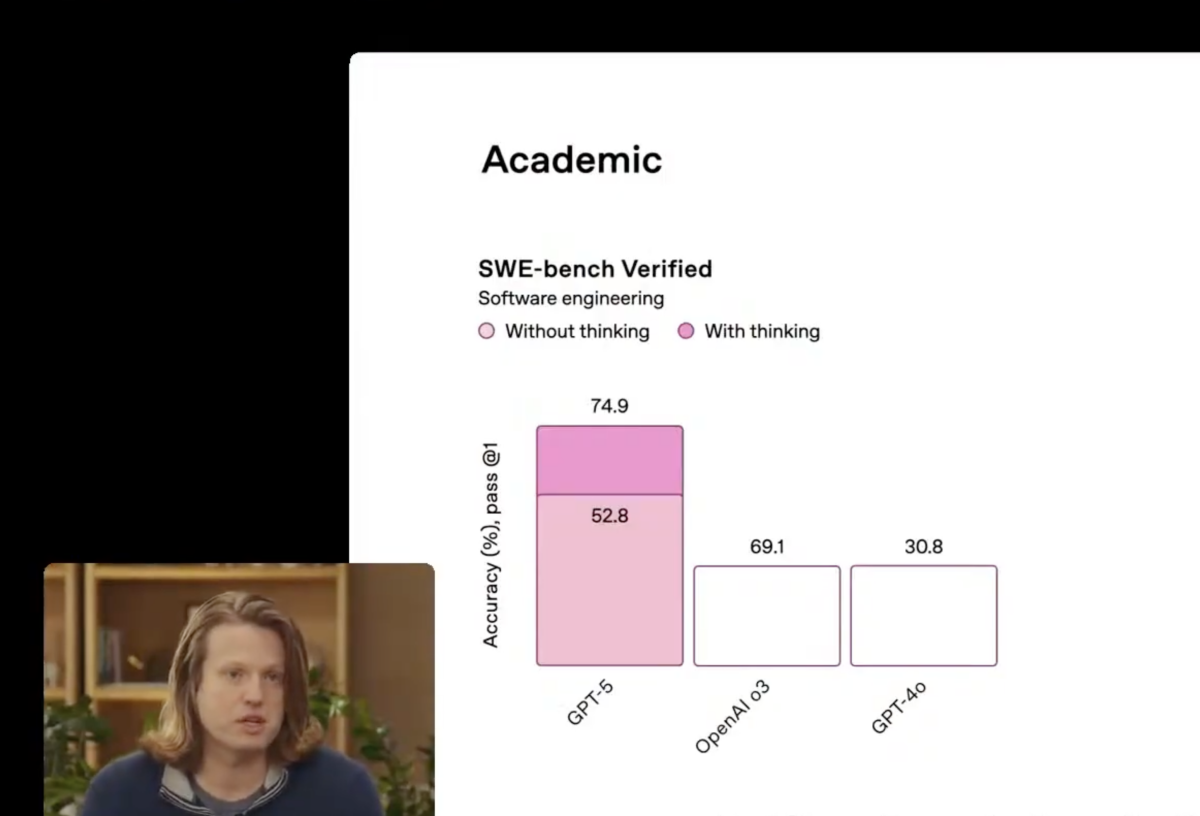
既然GPT-5的提升如此顯著,為何評價還會兩極分化?先說說發(fā)布會上出現(xiàn)的低級錯誤,比如在介紹GPT-5性能時OpenAI播放的幾頁P(yáng)PT,實在是讓人捉摸不透,這神奇的圖表也成為發(fā)布會的一大亮(槽)點(diǎn),52.8>69.1,讓人質(zhì)疑OpenAI的嚴(yán)謹(jǐn)性。奧特曼用“GPT-6來改進(jìn)”的調(diào)侃緩解尷尬,但網(wǎng)友似乎并不買賬。除此之外還有演示中神奇的大炮軌跡...也是讓人無力吐槽。
另外,盡管OpenAI表示GPT-5的幻覺率大幅降低,但在實際測試中,模型仍會因訓(xùn)練數(shù)據(jù)的局限性而犯錯。官方Demo里“幻覺降低”的片段,被網(wǎng)友揪出了錯誤。
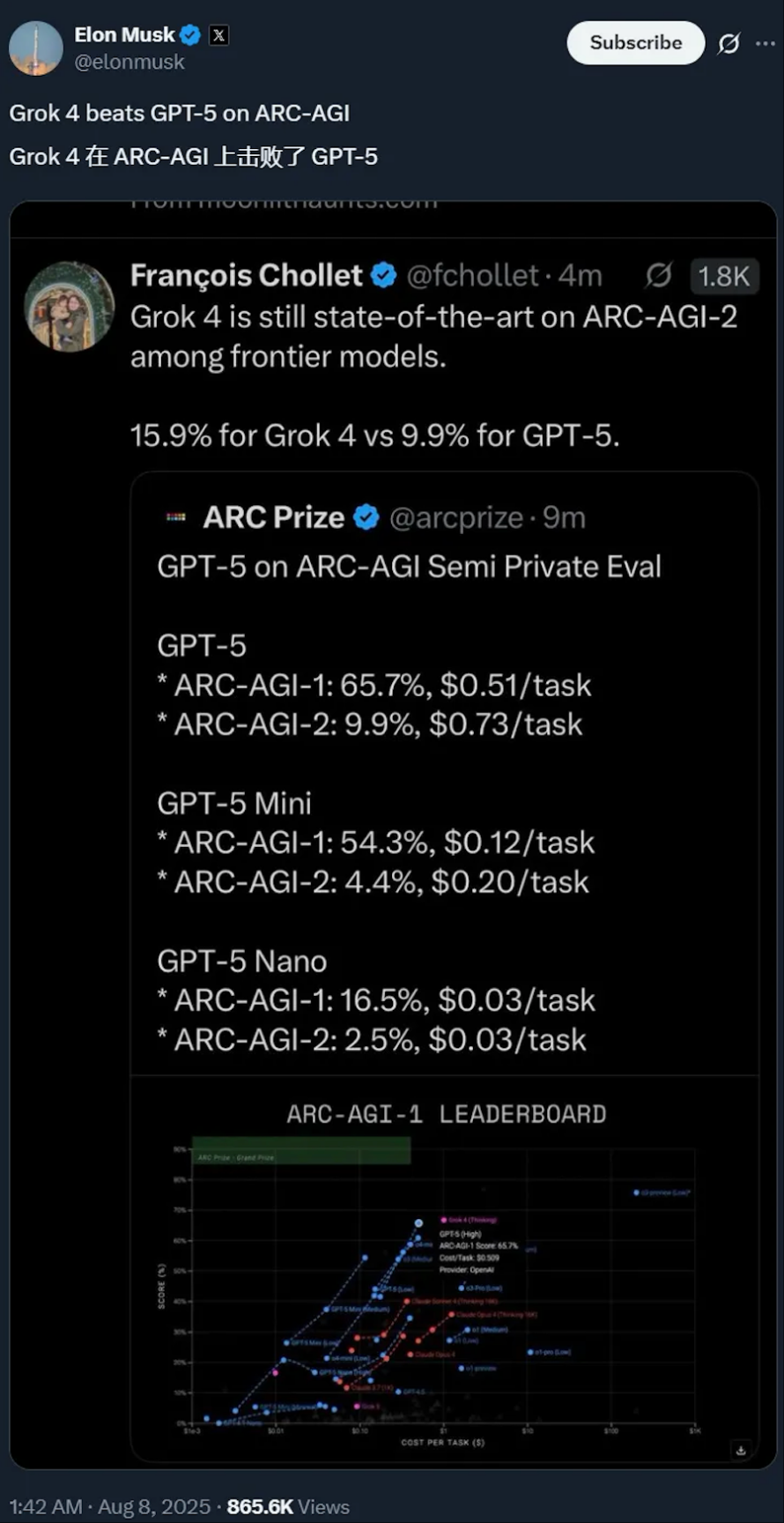
GPT-5的發(fā)布并未讓競爭對手沉默。馬斯克也趕來補(bǔ)刀,轉(zhuǎn)發(fā)GPT-5在ARC-AGI-2測試中未能擊敗Grok 4的截圖。并表示在今年年底前發(fā)布Grok 5。
寫在最后:
盡管GPT-5存在爭議,但不可否認(rèn)的是,這款模型正悄然重塑人類與AI的關(guān)系——從工具,到伙伴,再到如今潛在的“超級智能”。那么,在你看來這個口袋里的“博士級專家團(tuán)隊”表現(xiàn)是否超預(yù)期?
供稿單位:重慶天極網(wǎng)絡(luò)有限公司
審核專家:李志高 高級工程師/重慶天極網(wǎng)絡(luò)有限公司總裁
聲明:除原創(chuàng)內(nèi)容及特別說明之外,部分圖片來源網(wǎng)絡(luò),非商業(yè)用途,僅作為科普傳播素材,版權(quán)歸原作者所有,若有侵權(quán),請聯(lián)系刪除。

來源: 重慶市科學(xué)技術(shù)協(xié)會
內(nèi)容資源由項目單位提供
