
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 返樸
返樸 
2025年7月2日,加州大學圣地亞哥分校神經科學博士生李濟安在Nature發表研究,他從物理學理論中找到了理解神經科學的奇妙角度——從動力系統出發的公式發現,基于此構建了一種結構極簡、完全數據驅動的模型,能夠在無需任何人為假設的前提下,捕捉復雜且非最優的行為模式,在行為預測精度上全面優于傳統模型。這為生物體策略行為提供了一種可計算、可視化且易于理解的抽象結構。
撰文 | 路飛
自亞里士多德提出“人是理性的動物”這一經典論斷,理性便被視作人類行為決策的核心原則。從經濟學中的“理性人”假設,到決策理論中對最優選擇的追求,諸多思想與研究都暗含著對人類決策理性的肯定。著名認知心理學家、普林斯頓大學教授丹尼爾·卡尼曼在其暢銷書《思考,快與慢》中向世人拋出一個重要問題,“人類究竟有多理性?”有意思的是,雖然諾貝爾獎中沒有心理學獎,但是丹尼爾·卡尼曼作為認知心理學家,憑借著對于人的行為決策方面的研究貢獻,于2002年獲得了諾貝爾經濟學獎。在日常生活中,人們看似繁雜的決策背后,往往藏著對成本、收益與風險的權衡,這種基于理性的判斷貫穿于從日常購物到職業規劃的方方面面。
隨著人工智能技術的飛速發展,大模型正成為人類決策的重要輔助力量。從金融投資中的風險預測,到醫療診斷中的方案推薦,從城市交通的智能調度,到個人學習計劃的定制,大模型憑借對海量數據的分析能力和復雜邏輯的運算能力,不斷為人類提出更精準、高效的最優決策路徑,讓理性決策在更多領域得以延伸。比如,AlphaFold因為對蛋白質復雜結構的預測,獲得了2024年諾貝爾化學獎。
然而,人類決策機制的深層邏輯始終籠罩著一層神秘面紗。為何在相同信息下不同人會做出迥異選擇?決策過程中理性與直覺如何交織作用?這些問題推動著腦科學、神經科學與心理學等多學科展開持續探索。人工智能的飛速發展,正在重新激發人們對一個關鍵問題的關注:AI能否反過來幫助我們理解大腦?7月2日,加州大學圣地亞哥分校神經科學博士生李濟安在Nature發表研究,嘗試給出答案。

是“最優”的,但不是對的
如何理解文中提到的微型神經網絡模型,能夠刻畫生物體的策略學習過程,進而揭示決策行為中隱含的復雜認知機制?李濟安先從傳統認知模型構建娓娓道來。
在心理學和神經科學領域,研究者常通過計算模型解析生物體的認知過程,如感知、記憶、決策與學習機制。以決策為例,模型可幫助理解個體如何基于過往經驗,在多個選項中做出選擇。
傳統認知建模方法中,貝葉斯最優模型由研究者依據任務結構手動構建,其核心假設是生物體整合所有可用信息,以概率最優方式判斷。例如醫生診斷時綜合癥狀、檢驗結果、流行病趨勢與經驗積累證據,正是這種不確定信息整合的體現,該模型默認個體對信息和不確定性有最優估計。
另一類典型方法是強化學習模型,它假設人或動物通過與環境互動,從“獎勵”或“懲罰”中學習行為策略。比如在老虎機任務中,參與者經反復嘗試逐漸偏好中獎率更高的機器,這一通過獎勵優化策略的過程,可由強化學習算法模擬其行為價值更新機制。
這些模型具有一個共同特點:它們結構簡潔,參數量少,比如“學習率”(即控制新信息更新速度)和“決策噪音”(即干擾決策的影響因素,反映行為的隨機性),因此容易解釋和擬合。但恰恰因其簡潔性以及隱含的最優性假設,它們往往難以捕捉真實生物行為中普遍存在的復雜性與次優性。
例如實驗中觀察到,當獎勵結構發生改變后,動物常常仍固守之前的選擇偏好——即便新選擇更優。這種“固執”的行為現象很難被最優模型解釋。研究者往往需要在模型中人為增加額外的“慣性”參數,或設計特定規則來擬合實際行為。然而,隨著需解釋的行為細節不斷增多,模型結構會變得愈發繁瑣,充滿“補丁式”假設,這不僅容易引入主觀偏見,也使其難以推廣應用到其他情景任務中。
這是傳統認知模型一直為學界所詬病的弊端。
李濟安從2021年開始著手利用神經網絡研究人的行為決策,他想了解神經網絡學習人的行為決策背后的策略是什么。這是對傳統認知模型的直接亮劍,是否存在一種無需預設的建模方式,能夠讓模型直接從行為數據中“自主發現”策略?

李濟安 | 圖源:本人提供
得益于李濟安本科期間扎實的數理基礎,他從物理學公式中找到了理解神經科學的奇妙角度——從動力系統出發的公式發現。
“我是中國科學技術大學12級本科生,雖然我本科是生物學專業,但是科大的學生在本科期間數學和物理都是必修的,數理基礎比較好,業內人常說我們的數學課比其他數學專業的課程還難,我覺得這一定程度上影響了我的思維。”李濟安表示,“很多時候學了這些知識,當時可能沒覺得有用,但是可能在某一瞬間靈光乍現,所有學科是相通的。”
自動公式發現的核心基于符號回歸技術。與常見的函數擬合不同,擬合往往只是用已知函數形式去逼近數據,而符號回歸是在給定的函數庫(包含對數函數、三角函數、多項式函數等)中,通過組合和算術運算生成一個函數,力求精確擬合輸入輸出數據。例如在研究物體的運動軌跡時,符號回歸能從物體在不同時刻的位置、速度等數據里,找到描述其運動規律的準確公式,像勻加速直線運動的位移公式
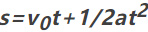
就有可能被自動發現。李濟安通過查閱資料發現,這一原理已經廣泛應用到物理、工程科學等領域中。
受此啟發,李濟安提出了一種新的方法:使用微型循環神經網絡(recurrentneuralnetwork,RNN)作為通用策略學習器,對個體的行為動態進行建模(圖1)。
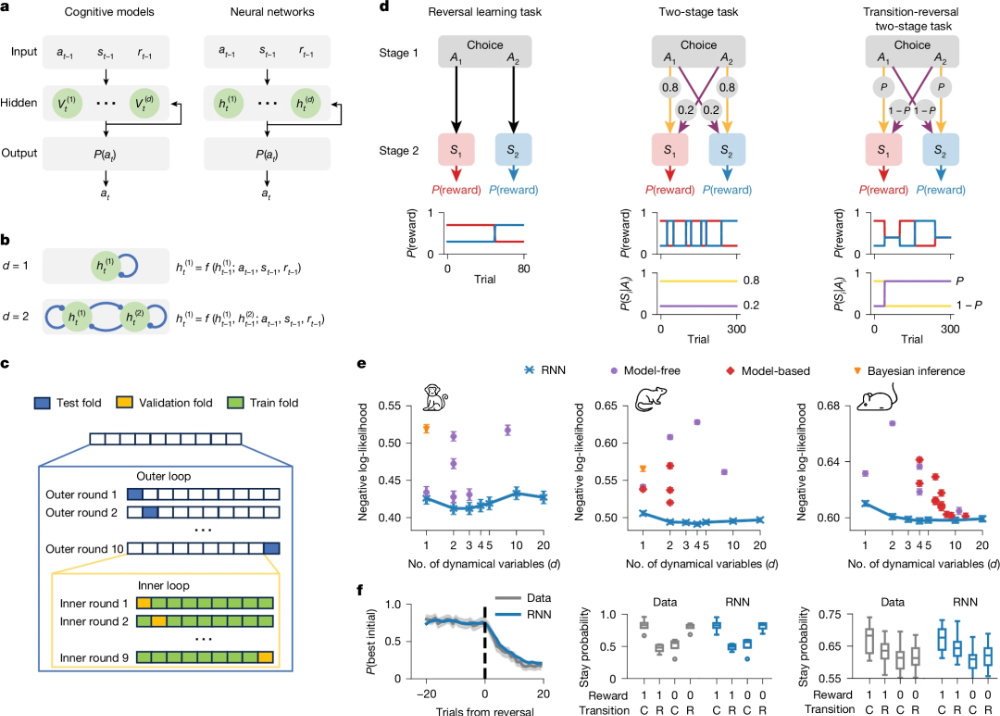
圖1 RNN模型概覽 | 圖源:論文
從物理學中的動力系統出發
循環神經網絡(RNN)是一類專為建模時間序列數據設計的神經網絡結構,其核心優勢在于能通過內部的循環連接機制,自動捕捉數據隨時間推移形成的動態依賴關系,比如行為序列中前后動作的關聯規律。
李濟安所采用的模型極具精簡性,僅包含1-4個神經單元。這種輕量化設計讓模型在保留對復雜行為模式足夠表達能力的同時,維持了較強的可解釋性,使得深入分析其內部神經元的活動機制與決策邏輯成為可能。
李濟安的核心研究問題是:這種結構極簡、完全數據驅動的模型,是否能夠在無需任何人為假設的前提下,捕捉復雜且非最優的行為模式——比如人們常常懶得換、愛用老辦法(“偏好保持”)或在“嘗鮮”和“吃老本”之間反復權衡(“探索-利用”權衡)等,它是否能夠在多樣化任務中超越傳統強化學習或混合策略模型的表現?
實驗結果顯示,這些微型循環神經網絡模型在六類經典獎勵學習任務中(涵蓋人類、猴子、小鼠、大鼠的行為數據)表現出色,在行為預測精度上全面優于傳統模型(如圖2所示),并可與更大規模的循環神經網絡相媲美(如圖3所示)。這表明,即便使用高度壓縮的網絡,它依舊能學會并舉一反三地模仿各種復雜決策,展現出用模型理解動物和人類的行為的巨大潛力。
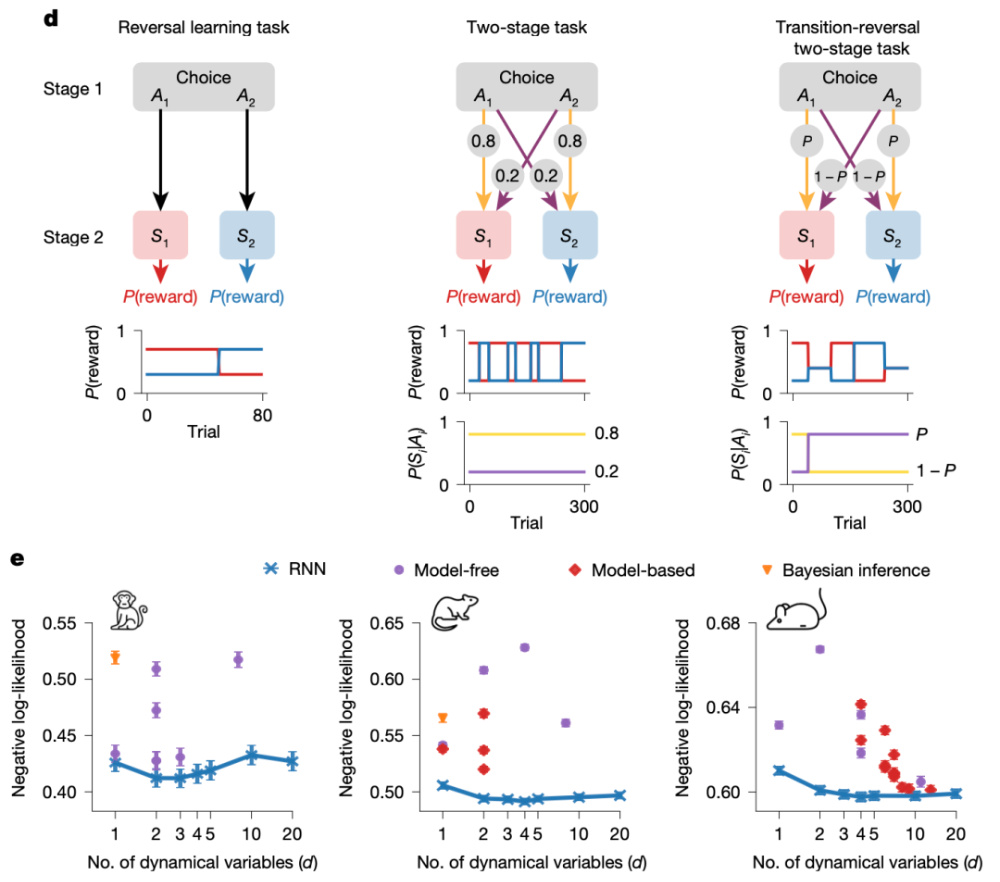
圖2 RNN在動物任務中的表現 | 圖源:論文
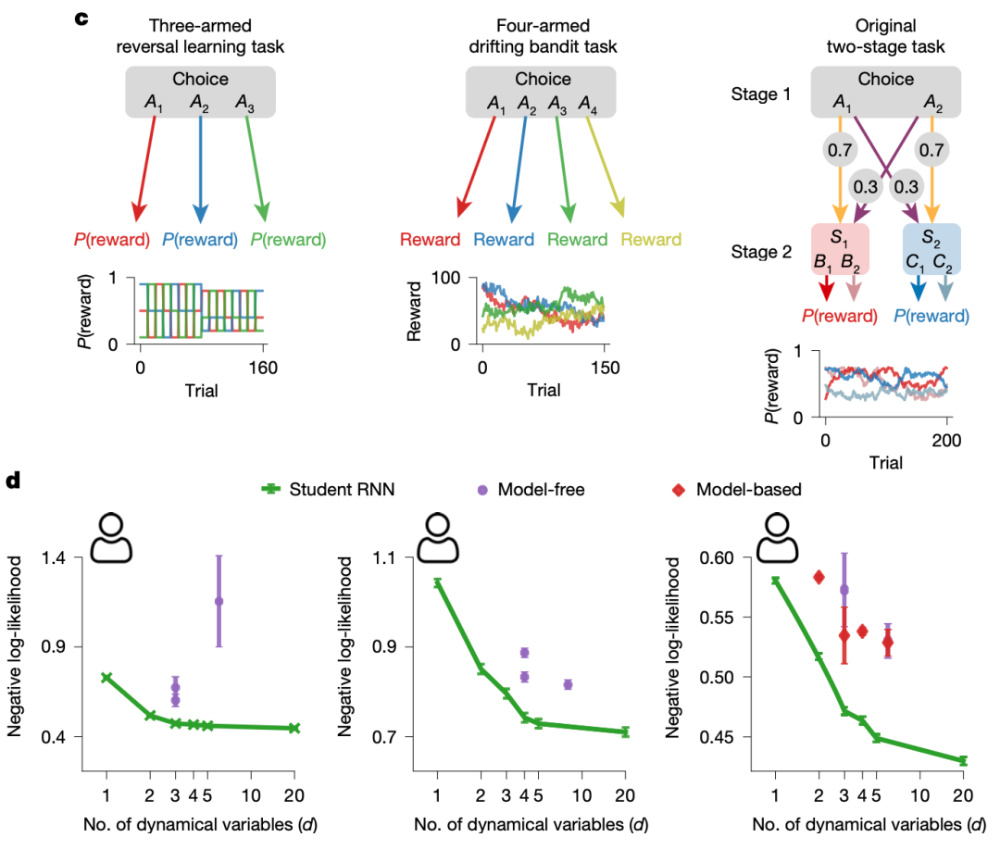
圖3 蒸餾模型的表現 | 圖源:論文
這些僅有1–4個神經元構成的RNN模型在行為預測上不僅準確,而且具備很強的可解釋性。“在模型中,動物行為的決策隨時間變化,我突然一瞬間就想到了物理學中研究小球的運動,需要記錄運動的方向、時間、距離等等。于是我就用物理學中的動力系統的分析方法,用一張圖來呈現決策過程,以當前動作偏好(Logit)為坐標、用箭頭或顏色指示下一步的變化方向與幅度。這是整個研究中最大的突破點。”李濟安解釋道,“這些圖片展示了不同模型在運行時的關鍵特點,比如哪些狀態是穩定的,哪些狀態會吸引模型靠近,以及模型如何在狀態間切換,清晰地呈現了動物的思維如何從一個想法或狀態轉變到另一個。”
李濟安從動力系統出發的研究方法,帶來了很多意料之外的發現。例如,某些行為策略會根據不同的狀態調整學習速度,類似人在不同情境下改變學習方式。此外,它還揭示了一些傳統方法難以發現的新心理機制,如獎勵后可能表現出“無所謂”傾向,決策時不再在意差別。
起初,2023年5月李濟安第一次投稿時,只用了三個動物的數據集。審稿人認為說服力不夠,“應用性不夠廣泛”。于是,他在二輪返稿的時候,補充了人類的數據集。結果同樣符合預期,審稿意見這才明朗起來。
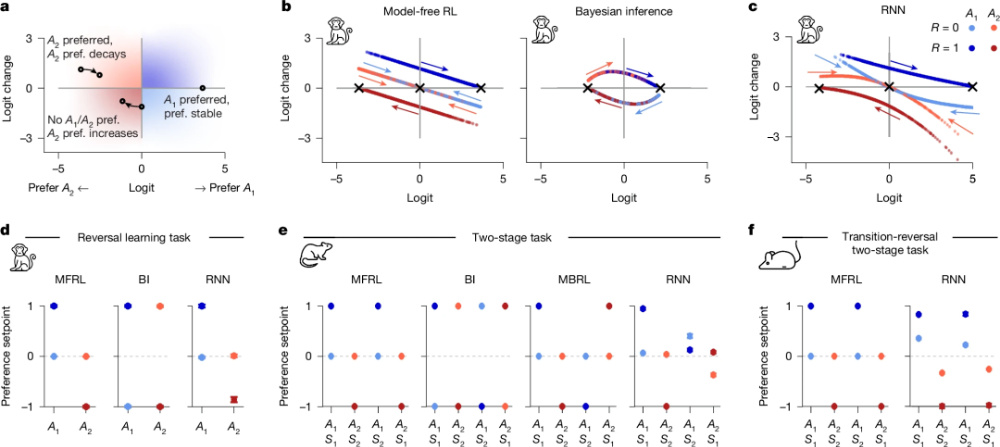
圖4 基于動力系統分析的模型解釋和比較
極具啟發性的是,李濟安發現即使是面對復雜任務,描述單個個體的行為所需的最小網絡維度也很低。這提示了每個受試對象在特定任務中的“最小行為維度”是有限的。這種從動力學系統出發的研究方法不僅有助于刻畫個體差異,也為認知建模提供了一個新的、可量化的指標來描述行為的復雜性。
最振奮人心的是,神經網絡在人們心中將會發生轉變,不再只是一個行為擬合的黑箱工具,而正在成為一種認知顯微鏡。神經網絡工具長期被喻為“黑箱”,其核心在于:數據輸入后經多層神經元的加權計算、特征傳遞最終輸出結果,但內部數據處理邏輯、特征提取過程與決策依據均難以用清晰直觀的方式解釋——人們能看到輸入與輸出,卻無法透視內部運作的“齒輪與鏈條”,這種不透明性也帶來了可解釋性不足的挑戰。
而李濟安他們的研究表明,神經網絡不僅具備數據驅動的建模能力,還能通過壓縮與適當的模型分析,揭示出潛在的行為生成機制。這項研究成果不僅擴展了認知建模的工具集,也為高可解釋性行為建模提供了新的方向。
這種研究范式與當前“AI for Science”的趨勢不謀而合,即:神經網絡作為模型發現的中介工具,能夠從高維實驗數據中提取結構化知識。為了實現知識的可解釋表達,需要找到適當的結構化表示形式。理想的表示形式應滿足兩點:一是具備良好的預測能力,二是對人類研究者而言語義清晰、邏輯透明。例如,AlphaFold在蛋白質建模中通過圖結構表示氨基酸間的幾何約束。
在該項研究中,這種結構化形式體現為低維離散動力系統,即只用少數幾個關鍵指標,描述和預測事件隨時間如何一步步變化。這為生物體策略行為提供了一種可計算、可視化且易于理解的抽象結構。
本碩博三個不同專業,只做一件事情
“要說從什么時候對大腦、神經、生物這些感興趣,應該要追溯到我小時候”,李濟安陷入思考。
李濟安1994年出生于安徽蕪湖,從小學就學習編程語言,參與電腦競賽班。初中起,他開始對生物感興趣。由此,他憑借生物競賽和計算機競賽保送中國科學技術大學,2016年獲神經生物與生物物理理學學士、計算機科學與技術(雙)工學學士學位。2019年獲中國科學技術大學應用統計碩士學位。目前在加州大學圣地亞哥分校讀博,從事神經科學研究。
本碩博三個專業,乍一看毫不相關,但實則不然。本科期間,除了周末攻讀計算機課程,李濟安還加入了張效初老師的生命科學院認知神經心理學實驗室,這是他科研之路的開端。在研究中,他發現應用統計學是從事學術研究工作的工具和基礎,于是碩士轉向應用統計學。在此期間,他一邊跟隨統計學導師,一邊跟隨生物學導師,向著預測人類行為的方向持續深耕。
“其實現在很多研究人員都是交叉學科背景的,像做神經科學領域的,你會發現有人工智能的、統計學的、心理學的。我覺得學習研究是一個過程,做好前期充足的知識儲備,才可能會在潛移默化中迸發靈感。比如我一直沒有丟下AI的學習,沒有忽略研究工具的學習。”
在大語言模型能力持續發展的當下,AI與神經科學的關聯日益緊密,由此催生了新興的NeuroAI領域。這一領域主要關注兩個方向的探索:一是“用AI研究大腦”(AIforNeuro),希望借助AI技術自動處理神經數據、提取相關特征,通過人工神經網絡模擬神經元活動規律與認知過程,驗證或提出新的神經科學理論;二是“用大腦啟發AI”(NeuroforAI),希望借助神經科學技術理解AI系統的內部工作原理,基于生物大腦高效的信息處理方式,讓AI變得更聰明、更節能、更具類人性。
這項研究揭示了人工神經網絡可以幫助我們理解人類的認知機制,正如前文提及NeuroAI有兩個核心議題,李濟安的研究并沒有止步。
在本項研究塵埃落定之后,他接著去驗證了第二個議題,反過來嘗試用神經科學中的理論,來解釋大型語言模型(LLMs)所展現出的某些智能特性。結果表明,語言模型確實展現出一定程度的基于上下文學習的元認知能力:它們不僅能夠監控自己內部的神經狀態,還能在一定程度上對其進行調控。
末了,李濟安沉浸在研究中,臉上略顯興奮,“這種互為鏡像、相互促進的智能理解體系,正是NeuroAI所描繪的愿景。”

特 別 提 示
1. 進入『返樸』微信公眾號底部菜單“精品專欄“,可查閱不同主題系列科普文章。
2. 『返樸』提供按月檢索文章功能。關注公眾號,回復四位數組成的年份+月份,如“1903”,可獲取2019年3月的文章索引,以此類推。
版權說明:歡迎個人轉發,任何形式的媒體或機構未經授權,不得轉載和摘編。轉載授權請在「返樸」微信公眾號內聯系后臺。
來源: 返樸
內容資源由項目單位提供
