
 科普中國公眾號
科普中國公眾號
 科普中國微博
科普中國微博

 幫助
幫助
 新疆維吾爾自治區(qū)巴音郭楞蒙古自治州尉犁縣科學技術協(xié)會
新疆維吾爾自治區(qū)巴音郭楞蒙古自治州尉犁縣科學技術協(xié)會 2024一開年,中美AI行業(yè)發(fā)生了兩件大事,進一步把1993年啟動的第三次人工智能浪潮推向高潮:OpenAI上線了GPT商店,AI的商業(yè)化進程更進一步;1月16日,中國智譜AI推出了比肩GPT-4的GLM-4大模型,為中國在全球AI領域的競爭增加了一份籌碼。
人工智能風云70余載,幾起幾落,沉沉浮浮,拼人才、拼算力、拼資金、拼算法,哪些故事需要銘記,哪些教訓又值得審視?
跨越七十年的華麗篇章
只為把“智能”裝進機器
阿蘭·圖靈是一位傳奇人物,他不僅僅是每一位當代程序員的“祖師爺”,圖靈還是一位世界級長跑運動員,馬拉松成績2小時46分03秒,只比1948年奧運會金牌成績慢11分鐘。二戰(zhàn)期間,他領導“Hut 8”小組破譯德軍密碼,成為盟軍在大西洋戰(zhàn)役中擊敗軸心國海軍的關鍵因素。

圖靈也是個馬拉松運動員|midjourney
當然,我們今天要說的還是“人工智能”。
圖靈被譽為計算機科學與人工智能之父,1950年,圖靈第一次提出“機器智能(Machine Intelligence)”的概念,“人類利用可用信息和推理來解決問題并做出決策,那么為什么機器不能做同樣的事情呢?”
自那時開始,無數(shù)科學家、科技企業(yè)為之奮斗——賦予機器以“智能”的革命悄然拉開了序幕。70多年過去,“三次浪潮,兩次低谷”, 人工智能終究是沖破層層阻隔,進入了大眾的日常生活。
縱觀三次人工智能浪潮,我們會發(fā)現(xiàn)一個有意思的現(xiàn)象:理論總是比現(xiàn)實更超前。不是科學家設計不出更好的人工智能,而是囿于當時的計算機技術,無法做到。
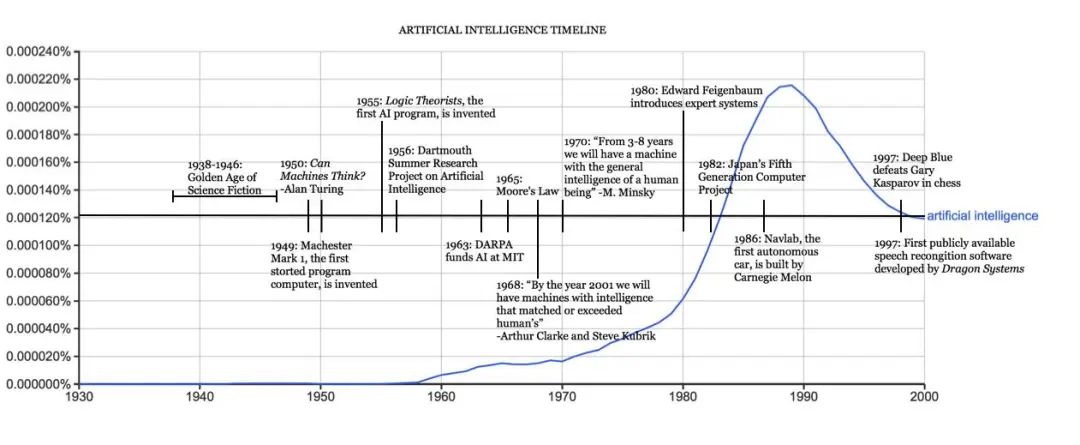
人工智能發(fā)展大事年表|哈佛大學官網(wǎng)
圖靈在1950年的論文《計算機器與智能》中已經(jīng)提出了機器思維的概念和著名的圖靈測試,是什么阻止了圖靈開始工作?有兩個原因。首先,在那個年代,計算機缺乏智能的一個關鍵先決條件:它們無法存儲命令,只能執(zhí)行命令。這意味著,計算機只能被告知要做什么,但是不記得自己做了什么。第二,計算成本在上世紀50年代太昂貴了,租賃一臺電腦每個月需要20萬美元,筆者根據(jù)通貨膨脹率做了換算,這相當于現(xiàn)在每月租金254萬美元,名副其實的**“有錢人的游戲”**。

名副其實的“有錢人的游戲”|midjourney
科學家之所以稱之為科學家,是因為他們的研究總是著眼于未來,即使當下缺乏變成現(xiàn)實的條件。
圖靈發(fā)表那篇著名的論文后僅兩年,計算機科學家阿瑟·薩繆爾(Arthur Lee Samuel)開發(fā)出一款跳棋程序,并提出了**“機器學習”**這個概念。1956年的達特茅斯會議上,約翰·麥卡錫(John McCarthy)正式提出了“人工智能”這個詞語,1956年,也就成為了實際意義上的人工智能元年。
至此,“人工智能”跨越了混沌初開的早期階段,進入了一個高速發(fā)展時期。多年后,當大眾回看那個時代,稱之為人工智能的**“第一次浪潮”**。

計算機科學與人工智能之父——阿蘭·圖靈
我們先來看看“第一次浪潮”給我們今天的生活留下了哪些遺產(chǎn)吧。說出來可能有些驚訝,我們今天使用的大多數(shù)軟件追根溯源都是“第一次浪潮”的產(chǎn)物,或者說,基于一種叫“手動編碼知識(Handcrafted Knowledge)”的人工智能。比如我們的Windows系統(tǒng),智能手機應用程序,人行道上按下按鈕等待紅燈變綠的交通燈。這些都是人工智能(此處采用第一次浪潮中對人工智能的定義)。
這真算“人工智能”?
算。
人們對人工智能的理解一直在變化。30年前,如果你問路人,谷歌地圖算不算人工智能,得到的答案是肯定的。這個軟件能幫你規(guī)劃最佳路線,還能用清晰的語言告訴你如何行駛,為什么不算?(谷歌地圖應用確實是第一波人工智能的典型案例)
第一次人工智能浪潮主要基于清晰且邏輯的規(guī)則。系統(tǒng)會檢查需要解決的每種情況下最重要的參數(shù),并就每種情況下采取的最適當?shù)男袆拥贸鼋Y論。每種情況的參數(shù)均由人類專家提前確定。因此,這種系統(tǒng)很難應對新的情況。他們也很難進行抽象——從某些情況中獲取知識和見解,并將其應用于新問題。
總而言之,第一波人工智能系統(tǒng)能夠為明確定義的問題實現(xiàn)簡單的邏輯規(guī)則,但無法學習,并且很難處理不確定性。
1957年,羅森布拉特發(fā)明感知機,這是機器學習人工神經(jīng)網(wǎng)絡理論中神經(jīng)元的最早模型,這一模型也使得人工神經(jīng)網(wǎng)絡理論得到了巨大的突破。樂觀的情緒在科學界蔓延,第一次人工智能浪潮逐漸被推向了高潮——挫敗要來了。

感知器原理圖|加利福尼亞州立大學
1966年,人們發(fā)現(xiàn)好像人工智能的路走歪了。邏輯證明器、感知器、強化學習等等只能做很簡單、非常專門且很窄的任務,稍微超出范圍就無法應對。為了更好的理解,我們建議讀者腦補使用Windows系統(tǒng)的體驗:一切功能都是提前設計好的,你無法教會這個系統(tǒng)做什么事,它也無法自己學習額外的知識。
另一方面,當時的計算機面臨內(nèi)存有限和處理速度不足的挑戰(zhàn),解決實際的人工智能問題變得十分困難。研究者們迅速認識到,要求程序具備兒童般的世界認知水平是一個過高的期望。在那個時候,沒有人能夠構建出滿足人工智能需求的龐大數(shù)據(jù)庫,也沒有人知道如何讓程序獲取如此豐富的信息。與此同時,許多計算任務的復雜度呈指數(shù)級增加,使得完成這些任務變得幾乎不可能。
科學家進入了死胡同,人工智能發(fā)展也進入了“蟄伏期”。
這一等,就是十多年。
當時間來到了20世紀80年代,兩個關鍵突破重新點燃了“第二次人工智能浪潮”:深度學習和專家系統(tǒng)。
約翰·霍普菲爾德 (John Hopfield) 和大衛(wèi)·魯梅爾哈特 (David Rumelhart) 推廣了“深度學習”技術,使計算機能夠利用經(jīng)驗進行學習。這意味著人工智能可以處理那些“沒有提前設定”的問題,它具備了學習能力。另一方面,愛德華·費根鮑姆(Edward Feigenbaum)引入了專家系統(tǒng),它模仿了人類專家的決策過程。
總的來說,第二次人工智能浪潮改變了人工智能的發(fā)展方向。科學家放棄了符號學派思路,改用統(tǒng)計學的思路來研究人工智能。深度學習和專家系統(tǒng)的引入讓機器能夠根據(jù)領域內(nèi)的專業(yè)知識,推理出專業(yè)問題的答案。
因此,第二次人工智能浪潮也叫**“統(tǒng)計學習(Statistical Learning)”時代**。
關于這一次浪潮,筆者想要強調(diào)兩點,第一,為何它如此重要?第二,它無法克服的弊端是什么?
第二次浪潮時間很短,但通過引入“統(tǒng)計學習系統(tǒng)”,工程師和程序員不會費心去教授系統(tǒng)要遵循的精確規(guī)則(第一次浪潮的理念)。相反,他們?yōu)槟承╊愋偷膯栴}開發(fā)統(tǒng)計模型,然后在許多不同的樣本上“訓練”這些模型,使它們更加精確和高效。
此外,第二波系統(tǒng)還引入了人工神經(jīng)網(wǎng)絡的概念。在人工神經(jīng)網(wǎng)絡中,數(shù)據(jù)經(jīng)過計算層,每個計算層以不同的方式處理數(shù)據(jù)并將其傳輸?shù)较乱粋€級別。通過訓練每一層以及整個網(wǎng)絡,它們可以產(chǎn)生最準確的結果。

神經(jīng)網(wǎng)絡示意圖|Pixabay
這些都為第三次人工智能浪潮奠定了基礎,而且留下了龐大的遺產(chǎn),我們今天依然在使用。比如人臉識別、語音轉錄、圖片識別,以及自主汽車和無人機的部分功能,都來自于這次浪潮的成果。
但是,這套系統(tǒng)有一個巨大的弊端。根據(jù)美國國防高級研究計劃局(DARPA)指出,我們尚不清楚人工神經(jīng)網(wǎng)絡背后的實際運行規(guī)則,也就是說,這套系統(tǒng)運行良好,但是我們不知道為什么運行的這么好。這就好比人可以把球拋到空中,并且能大概判斷球會落在哪里,如果你問他,你是如何做出判斷的,是根據(jù)牛頓力學定律計算的嗎?他無法回答,但他就是知道。
這暴露了一種因果關系挑戰(zhàn),因為“看不到因果”。第二套系統(tǒng)依賴數(shù)據(jù)輸入,數(shù)據(jù)輸出做決策,缺乏因果會導致嚴重后果:這個系統(tǒng)容易學壞。
微軟曾經(jīng)設計了一個機器人叫“Tai”,他可以順暢的和人聊天,但如果有越來越多的人告訴他“希特勒是個好人”,它就會逐漸接受這個結論。
這些難題,留給了第三次人工智能浪潮來解決。
這次浪潮也是目前我們所正在經(jīng)歷的,也稱之為**“情景適應(Contextual Adaptation)”**。如果非要確定一個時間節(jié)點,應該是1993年之后。摩爾定律讓計算機算力急速提升,大數(shù)據(jù)的發(fā)展讓海量數(shù)據(jù)存儲和分析成為可能。

來源:開源圖庫Pixabay
為了更好的說明和上一次人工智能浪潮的區(qū)別,我們可以用一張圖片舉例。如果用第二次的系統(tǒng)來回答“圖片里的動物是什么?”你會得到“圖片里是一頭牛的可能性為87%”。如果同樣的問題給到第三次系統(tǒng),它不僅告訴你這是一頭牛,還會給出符合邏輯的理由,比如四只腳、有蹄子,身上有斑點等等。
換句話說,第三次的系統(tǒng)更講邏輯。
筆者認為,第三次人工智能浪潮有3個重要節(jié)點(通常認為是前兩個)。2006年,杰弗里·辛頓(Geoffrey Hinton)發(fā)表了《一種深度置信網(wǎng)絡的快速學習算法》,在基層理論上取得若干重大突破。2016年,谷歌DeepMind研發(fā)的AlphaGo在圍棋人機大戰(zhàn)中擊敗韓國職業(yè)九段棋手李世乭,這標志著“人工智能”從科研領域開始邁向公眾領域,從學術主導走向商業(yè)主導。
此后便是2022年11月30日,OpenAI發(fā)布ChatGPT,讓AI成為了一款消費級產(chǎn)品。**“生成式AI”和“大語言模型”**一時成為大眾熱議的焦點。
生成式AI的競賽,
我們要拼的是什么?
“生成式AI”是人工智能的一個分支,通過利用大型語言模型、神經(jīng)網(wǎng)絡和機器學習的強大功能,能夠模仿人類創(chuàng)造力生成新穎的文字、圖片和音、視頻等內(nèi)容。
大眾看到的OpenAI有多輝煌,那成立之初就有多落寞。那時候的OpenAI面臨兩個困境:一是缺乏資金,二是其技術路線不被主流所認可。
根據(jù)機構測算,直到2019年OpenAI共接受的捐助總額僅為1.3億美元,也就10億人民幣,馬斯克個人捐助最多。當然,這點錢和國內(nèi)創(chuàng)業(yè)公司動輒上百億的融資比不值一提。由于缺乏資金,OpenAI不得不依靠捐贈,2016年,英偉達贈送給OpenAI一臺DGX-1超級計算機,幫助其縮短了訓練更復雜模型的時間(從6天到2小時)。
2018年,就連之前的最大捐贈來源馬斯克也離開了OpenAI。他曾經(jīng)提議接管OpenAI,但遭到董事會拒絕,于是離開,并且此后沒有再進行捐贈。
另外一方面,OpenAI選擇了一條不好走的路——先研發(fā)預訓練模型。2018年,OpenAI推出了具有1.17億個參數(shù)的GPT-1(Generative Pre-training Transformers, 生成式預訓練變換器)模型,這一年也叫預訓練模型元年。
為何這個于預訓練模型的發(fā)布如此重要?這標志著AI進化路線的轉變,在此之前,的神經(jīng)網(wǎng)絡模型是有監(jiān)督學習的模型,存在兩個缺點:
首先,需要大量的標注數(shù)據(jù),高質(zhì)量的標注數(shù)據(jù)往往很難獲得,因為在很多任務中,圖像的標簽并不是唯一的或者實例標簽并不存在明確的邊界;第二,根據(jù)一個任務訓練的模型很難泛化到其它任務中,這個模型只能叫做“領域?qū)<摇倍皇钦嬲睦斫饬薔LP(自然語言處理)。
預訓練模型則很好的解決了上述問題。
2020年,OpenAI發(fā)布了第三代生成式預訓練 Transformer,即GPT-3。這一事件同樣成為了大洋彼岸另一家中國AI初創(chuàng)企業(yè)的轉折點——智譜AI。
GPT-3 的發(fā)布給了大家非常明確的信號,即大型模型真正具備了實際可用性。在反復糾結和討論后,智譜 AI 終于決定全面投身大模型,成為了國內(nèi)較早介入大模型研發(fā)的企業(yè)之一。
同樣,智譜AI投入了大量的研發(fā)資源在預訓練模型上。2022年,GLM-130B發(fā)布,斯坦福大學大模型中心對全球30個主流大模型進行了全方位的評測,GLM-130B 是亞洲唯一入選的大模型。評測報告顯示GLM-130B在準確性和公平性指標上與GPT-3 175B (davinci) 接近或持平,魯棒性、校準誤差和無偏性優(yōu)于GPT-3 175B。

實際上,GLM-130B是中國科技公司智譜AI發(fā)布的一個**“預訓練模型”**。“預訓練模型”是訓練“大預言模型”的模型。它的位置比大眾接觸到的“生成式AI”更加前置,是埋藏在海平面之下的基礎設施。現(xiàn)在市面上可供使用的預訓練模型不多,比較主流的是來自OpenAI的GPT,以及來自谷歌的Bert。GLM-130B正是結合了以上兩個框架優(yōu)點的國產(chǎn)自主研發(fā)預訓練模型。
智譜AI則是奮起直追,對標OpenAI,成為了阿國內(nèi)唯一一個對標OpenAI全模型產(chǎn)品線的公司。
2020年,OpenAI推出GPT-3
2021年,OpenAI推出DALL-E
2022年12月,OpenAI推出了轟動一時的ChatGPT
2023年3月,OpenAI推出GPT-4
對比智譜AI和OpenAI的產(chǎn)品線,我們可以看到:
GPT vs GLM
- ChatGPT vs. ChatGLM(對話)
- DALL.E vs. CogView(文生圖)
- Codex vs. CodeGeeX (代碼)
- WebGPT vs. WebGLM (搜索增強)
- GPT-4V vs. GLM4 (CogVLM, AgentTuning) (圖文理解)
為何搶占生成式AI的高地如此關鍵?
2023年的一句論斷可以回答這個問題,“所有產(chǎn)品都值得用AI重做一遍”。AI對各個行業(yè)的的效率提升是革命性的,這種提升發(fā)生在服務業(yè)、新藥研發(fā)、網(wǎng)絡安全、制造業(yè)升級各個方面。
根據(jù)中國信通院的數(shù)據(jù),2023年中國的人工智能專利申請量和論文發(fā)表量都位居世界第一,中國的人工智能市場規(guī)模也在不斷擴大,預計到2023年將達到5132億美元,占全球的近四分之一。
“工欲善其事必先利其器”。在“利器”GLM-130B訓練下,智譜在2023年10月推出了自研第三代對話大模型 ChatGLM3,此時距離發(fā)布上一代產(chǎn)品ChatGLM2僅過去4個月。
2024年1月16日,距離ChatGLM3發(fā)布不到3個月,公司又推出了GLM-4,GLM-4 相比 GLM-3 性能全面提升 60%。其各項參數(shù)已經(jīng)達到了比肩GPT-4的程度。在基礎能力指標MMLU 81.5、GSM8K 87.6、MATH 47.9和BBH 82.25等項目上,GLM-4已經(jīng)達到GPT-4 90% 以上水平。HumanEval 72 達到 GPT-4 100%水平。
對齊能力上,基于AlignBench數(shù)據(jù)集,GLM-4超過了GPT-4在6月13日發(fā)布的版本,逼近GPT-4最新效果,在專業(yè)能力、中文理解、角色扮演方面超過GPT-4精度。
GLM-4 還帶來了 128K 上的長文本能力,單次提示詞可處理文本達到 300 頁。在 needle test 大海撈針測試中,128K 文本長度內(nèi) GLM-4 模型均可做到幾乎百分之百精度召回。
同時,GLM-4大大增強了多模態(tài)能力以及Agent能力,GLM-4 可以實現(xiàn)自主根據(jù)用戶意圖,自動理解、規(guī)劃復雜指令,自由調(diào)用WebGLM搜索增強、Code Interpreter代碼解釋器和多模態(tài)生成能力以完成復雜任務。GLMs個性化智能體定制能力也同步上線。不需要代碼基礎,用戶用簡單的提示詞指令就能創(chuàng)建屬于自己的GLM智能體。
其實智譜AI的發(fā)展路徑也符合AI行業(yè)的內(nèi)在規(guī)律。“人工智能不是一個簡單的從1到100進步的過程,它往往趨向于兩個極端:要么90分以上,其它的都是10分以下。”換言之,要么“快速突破”,要么“原地打轉”,不奮力前進就只能滑入另一個極端。
回到歷史時間線里,我們目前正處在第三次人工智能浪潮當中,既然有浪潮,就有高潮與低谷。第三次浪潮會結束,什么才是推動它的關鍵?
有一種觀點認為“深度學習算法”帶來的技術紅利,將會支撐我們前進5-10年,隨后瓶頸就會到來。在瓶頸到來之前,我們急切需要一個“技術奇點”拿過接力棒,把這次浪潮推到更高的高度。
“技術奇點”在哪里尚不可知。但有一點可以確定,它的出現(xiàn)有賴于企業(yè)的長期投資、深度研發(fā)和對科技的信念。
來源: 果殼
